
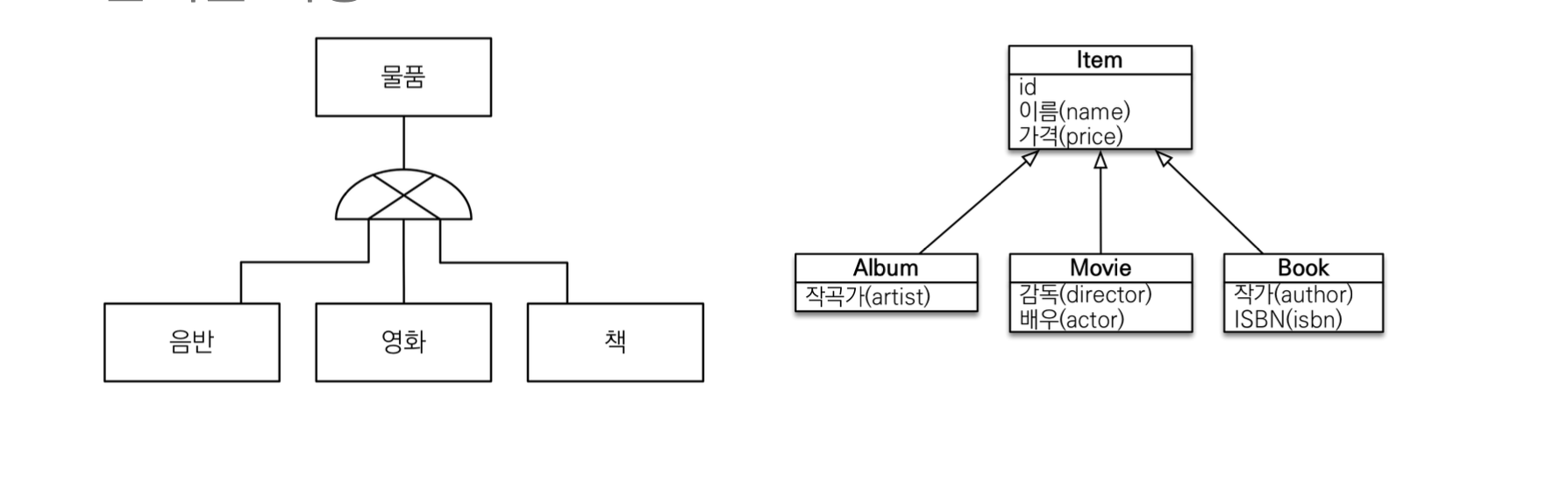
상속관계 매핑
RDB는 물리모델 , 객체의 상속관계는 논리모델
JPA는 어떤 물리모델을 갖던, 객체로의 논리모델 지원한다.
특징
- 관계형 데이터베이스는 상속 관계 X
- RDB에는 대신 슈퍼타입 서브타입 관계라는 모델링 기법이 객체 상속과 유사
- 객체에서는 상속관계 매핑: 객체의 상속과 구조와 DB의 슈퍼타입 서브타입 관계를 매핑
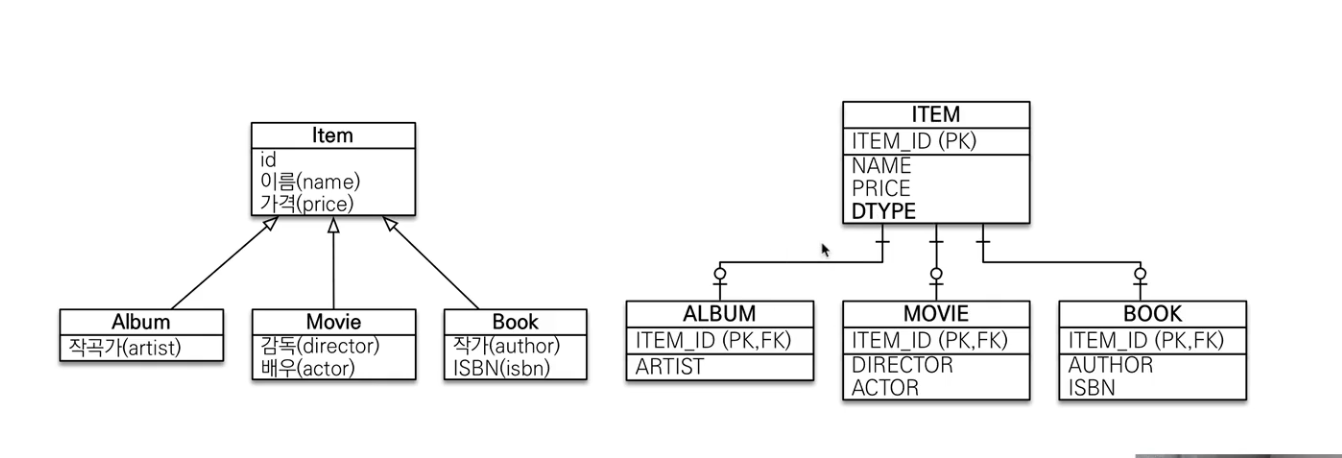
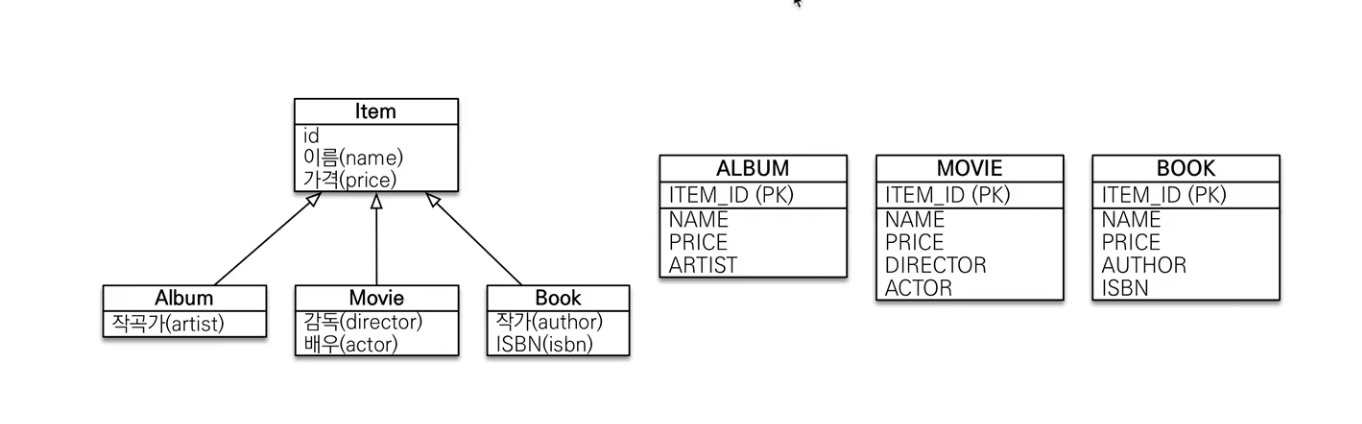
조인 전략
- Insert 할때는 2번이 일어나며, 조회를 할때는 pk, fk값으로 조인해서 가져오고, DTYPE을 정해서 해당하는 table과의 조인을한다.
- 주요 에너테이션
- @Inheritance(strategy=InheritanceType.XXX)
- JOINED: 조인 전략
- SINGLE_TABLE: 단일 테이블 전략
- TABLE_PER_CLASS: 구현 클래스마다 테이블 전략
- @DiscriminatorColumn(name=“DTYPE”)
- @DiscriminatorValue(“XXX”)
- @Inheritance(strategy=InheritanceType.XXX)
- 비즈니스적으로 어려울때, 할일많을때 선택
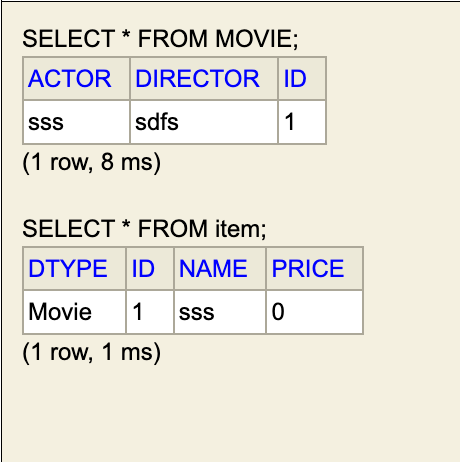
1 |
|
1 | Movie movie = new Movie(); |
장단점
장점
- 테이블 정규화
- 외래 키 참조 무결성 제약조건 활용가능
- 저장공간 효율화
단점
- 조회시 조인을많이사용, 성능저하
- 조회 쿼리가 복잡함
- 데이터 저장시 INSERT SQL 2번 호출
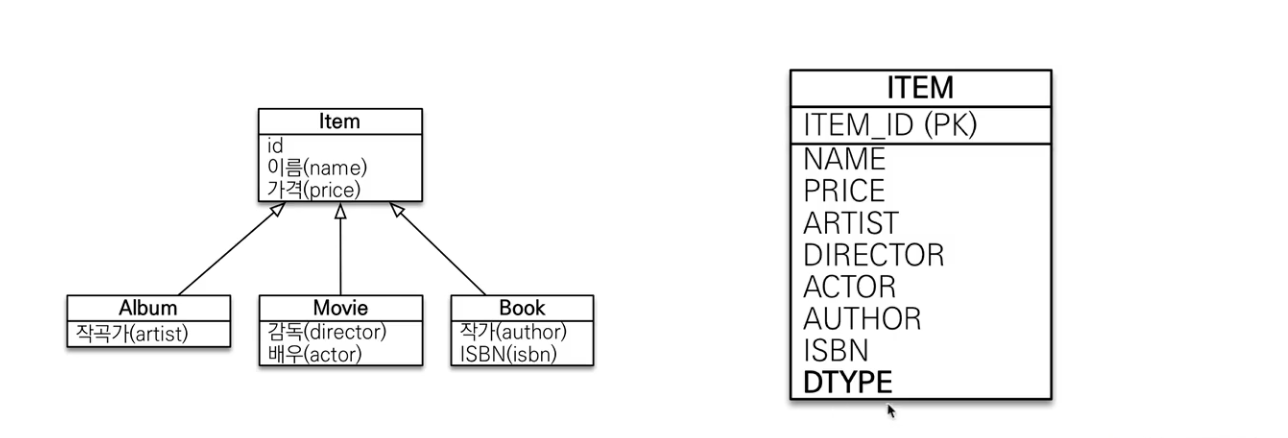
단일 테이블 전략
- 하나의 테이블로 구성한다.
- 단순하고 성능 의외로 좋음(쿼리 한번)
- @DiscriminatorColumn 없어도 필수로 어차피 생성됨
- 단순할때 사용
장단점
장점
- 조인이 필요 없으므로 일반적으로 조회 성능이 빠름
- 조회 쿼리가 단순함
단점
- 자식 엔티티가 매핑한 컬럼은 모두 null 허용
- 단일테이블에모든것을저장하므로테이블이커질수있다. -> 상 황에 따라서 조회 성능이 오히려 느려질 수 있다.
구현 클래스마다 테이블 전략
- 그냥 부모관계가 없이 각자 모든 정보를 갖는 테이블로 만듬
- 구체적인 테이블 만 만듬. 중복 테이블생겨도 그냥
1 |
|
1 | Item item = em.find(Item.class, movie.getId()); |
단점은 부모타입으로 조회할시,
unionALL 사용되고, 모든 테이블 검색해야만 데이터 찾을수있다.
장단점
이 전략은 데이터베이스 설계자와 ORM 전문가 둘 다 추천 X
장점
- 서브 타입을 명확하게 구분해서 처리할 때 효과적
- not null 제약조건 사용 가능
단점
- 여러 자식 테이블을 함께 조회할 때 성능이 느림(UNION SQL 필요)
- 자식 테이블을 통합해서 쿼리하기 어려움
- column 변경할때, 아주 어려움
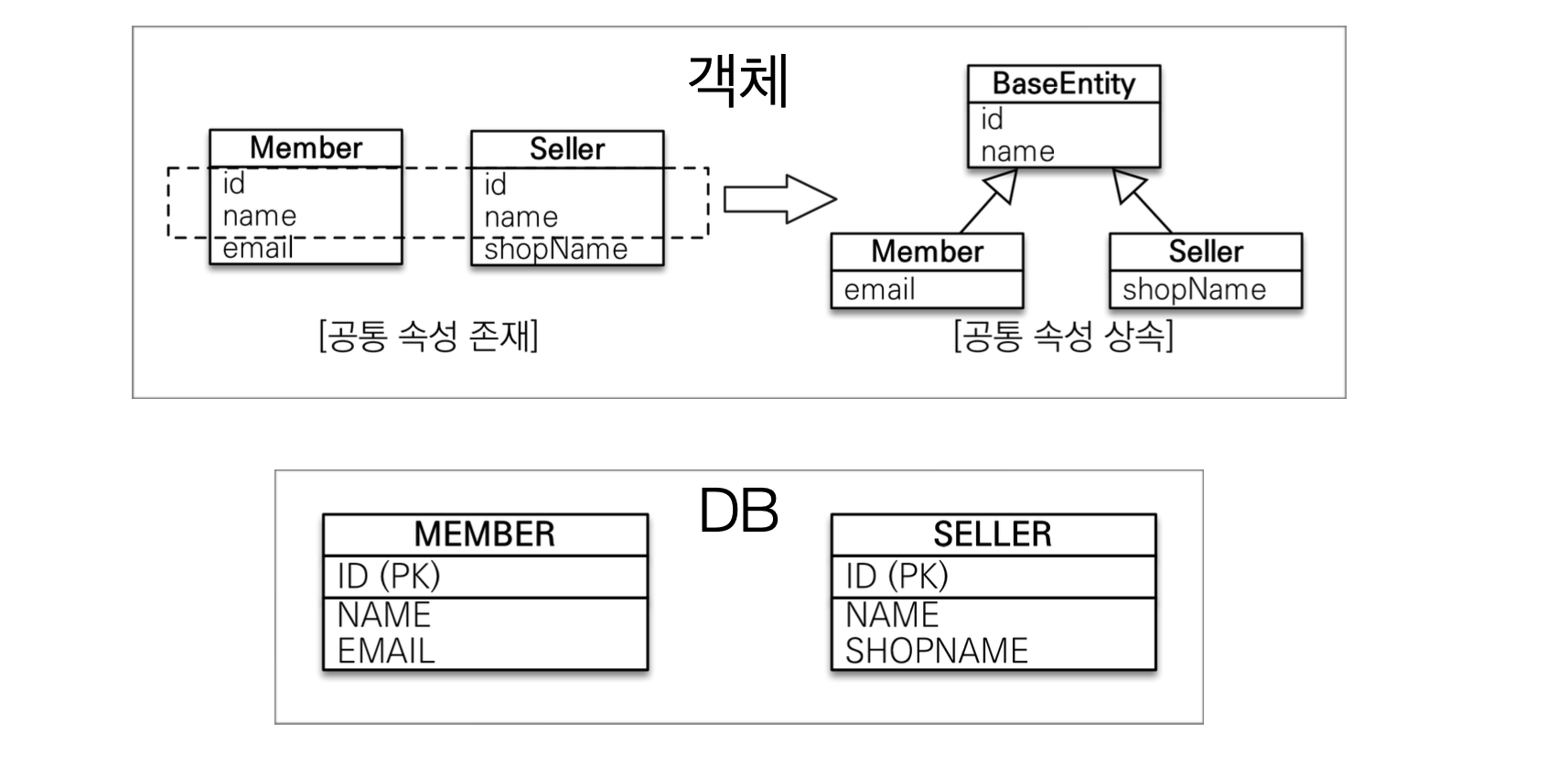
@MappedSuperclass
- 공통 매핑 정보가 필요할 때 사용(id, name)
- DB는 완전히 다른곳에 저장되어있지만(물리적분리됨), 객체에서는 공통 속성을 묶고싶을때 사용(논리적으로 공통화)
- 보통 모든 객체에 생성 수정날짜 넣고싶을때 등등 사용
1 |
|
1 |
|
특징
- 상속관계 매핑X
- 엔티티X, 테이블과 매핑X
- 부모 클래스를 상속 받는 자식 클래스에 매핑 정보만 제공
- 조회, 검색 불가(em.find(BaseEntity) 불가)
- 직접 생성해서 사용할 일이 없으므로 추상 클래스 권장
- 테이블과 관계 없고, 단순히 엔티티가 공통으로 사용하는 매핑 정보를 모으는 역할
- 주로 등록일, 수정일, 등록자, 수정자 같은 전체 엔티티에서 공통 으로 적용하는 정보를 모을 때 사용
- 참고: @Entity 클래스는 엔티티나 @MappedSuperclass로 지 정한 클래스만 상속 가능
애플리케이션에서의 고민
- 테이블을 단순하게 유지하는것이좋음
- 객체지향적으로 -> 설계하다가 너무 커지면, 싱글 테이블 혹은 JSON으로 말아넣는다