
DB에 대한 전반적인 개념
왜?
- DB에는 크게 SQL 과 no-SQL이있다는것을 알고있었지만, DB의 세부적인 구분과 각 DB의 장단점을 알아야 추후 프로젝트를 진행할때 필요하여 작성하게 되었다. DB를 자세히 알기전 용어정리후 큰그림부터 탑다운으로 내려가는 것으로 학습하였다.
- 먼저 RDB 위주의 개념 설명
- 추후: index, 쿼리, explain관련 내용 추가, marina db, progresql vacuum알아보기
RDB위주의 데이터 베이스(DB) 용어
- 관계형 데이터베이스(RDB): 여러개의 테이블이 특정 관계로 이루어져있는 구조를 가진 DB
Table관련 용어
- Relation(= Table): 관계형 데이터 베이스에서 정보를 구분하여 저장하는 기본 단위.
- Tuple(=Record): 테이블에서 행을 의미. 튜플은 릴레이션에서 같은 값을 가질 수 없다. 튜플의 수는 카디날리티(Cardinality)라고 한다.
- Attribute( =Field): 테이블에서 열을 의미. 같은 말로는 칼럼이라고도 하며 어트리뷰트의 수는 디그리(Degree)라고도 한다.
- 식별자(Identifier): 여러개의 집합체를 담고있는 관계형 데이터 베이스에서 각각의 구분할 수 있는 논리적인 개념
- 유일성: 하나의 릴레이션에서 모든 행은 서로 다른 키 값을 가져야 한다.
- 최소성: 꼭 필요한 최소한의 속성들로만 키를 구성해야 한다.
엔티티(Entity)
- 사람, 장소, 사물, 사건 등과 같이 독립적으로 존재하면서 고유하게 식별이 가능한 실세계의 객체. (ex) 사람(나이,이름, 주민번호…).>> 엔티티는 인스턴스의 집합이다
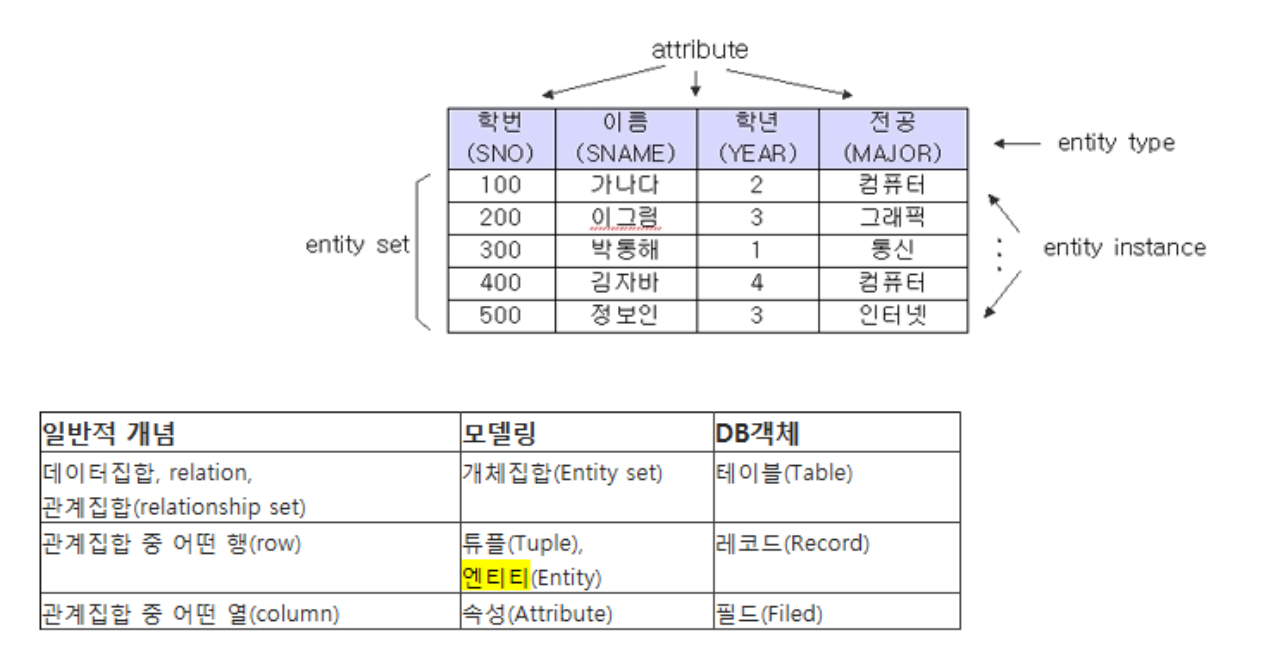
- 엔티티개념 → 물리적 DB객체
- Entity Set→ Table
- Attribute→coleum,field
- Entity instance → row,record
- Entity type → column set
- 엔티티 집합(Entity Set): 동일한 속성을 가진 엔티티의 집합. 엔티티 집합에 속한 여러 요소들이 여러 엔티티 집합에 속할수도있다.
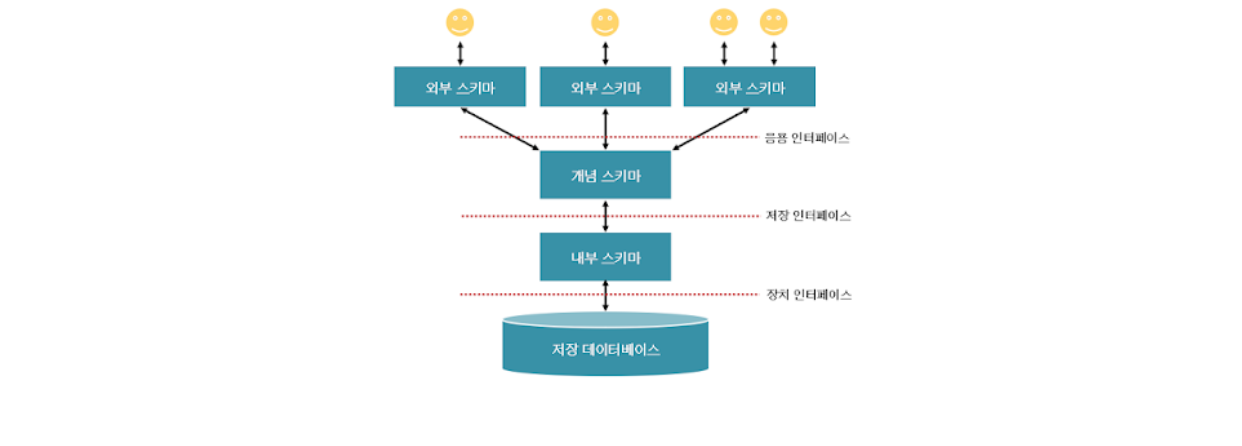
스키마(Schema)
- 스키마 : 데이터베이스 : 테이블 = 평면도 : 집 : 방
- DB의 구조를 전반적으로 기술한것(=설계도)
데이터 개체(Entity), 속성(Attribute), 관계(Relationship)등을 정의 한것을 말한다. 사용자의 관점에 따라 외부 스키마, 개념 스키마, 내부 스키마라 구분한다. RDBMS는 외부 스키마에 명세된 사용자의 요구를 개념 스키마 형태로 변환하고,이를 다시 내부 스키마 형태로 반환한다.- 외부 스키마(사용자 뷰): 사용자의 입장에서 정의한 데이터 베이스의 논리적 구조. 데이터들을 어떤 형식, 구조, 화면을 통해 사용자에게 보여줄 것인가에 대한 명세를 말하며 하나의 데이터베이스에는 여러개의 외부 스키마가 있을 수 있다. 일반 사용자는 SQL을 이용하여 DB를 쉽게 사용할 수 있다. 응용 프로그래머는 C, 자바 등의 언어를 사용하여 DB에 접근한다.
- 개념 스키마(전체적인 뷰):데이터베이스의 전체적인 논리적 구조. 모든 이용자가 필요로 하는 데이터를 총합한 조직 전체의 데이터 베이스로 하나만 존재한다. 개체 간의 관계와 제약조건, 데이터 베이스의 접근 권한, 보안 등에 관한 명세를 나타낸다. 데이터 베이스 관리자에 의해서 구성된다.
- 내부 스키마:물리적 저장장치의 입장에서 본 데이터베이스 구조. 실제로 데이터베이스에 저장될 레코드의 물리적인 구조, 저장 데이터 항목의 표현 방법, 내부 레코드의 물리적 순서 등을 나타낸다.
Key
- 데이터베이스에서 조건에 만족하는 튜플을 찾거나 순서대로 정렬할 때 튜플들을 서로 구문할 수 있는 기준이 되는 Attribute(속성)
키 종류
후보키(Cardidate Key)
- 릴레이션을 구성하는 속성들 중에서 튜플을 유일하게 식별하기 위해 사용하는 속성들의 부분집합.
- 기본 키로 사용할 수 있는 속성들을 의미.
- 모든 릴레이션에는 반드시 하나 이상의 후보키가 존재한다.
- 유일성과 최소성을 만족시켜야 한다.
기본키(Primary Key)
- 후보키 중에서 선택한 Main Key이다.
- 한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성.
- null 값을 가질 수 없다.
- 동일한 값이 중복되어 저장될 수 없다.
슈퍼키(Super Key)
- 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키로서 릴레이션을 구성하는 모든 튜플들 중 슈퍼키로 구성된 속성의 집합과 동일한 값을 나타나지 않는다.
- 릴레이션을 구성하는 모든 튜플에 대해 유일성을 만족시키지만, 최소성을 만족시키지 못한다.
- (ex) 학번 + 주민번호를 사용하여 슈퍼키를 만들면 유일성은 만족하지만, 학번이나 주민번호 하나만 가지고도 다른 튜플들을 구분할 수 있으므로 최소성은 만족시키지 못한다.
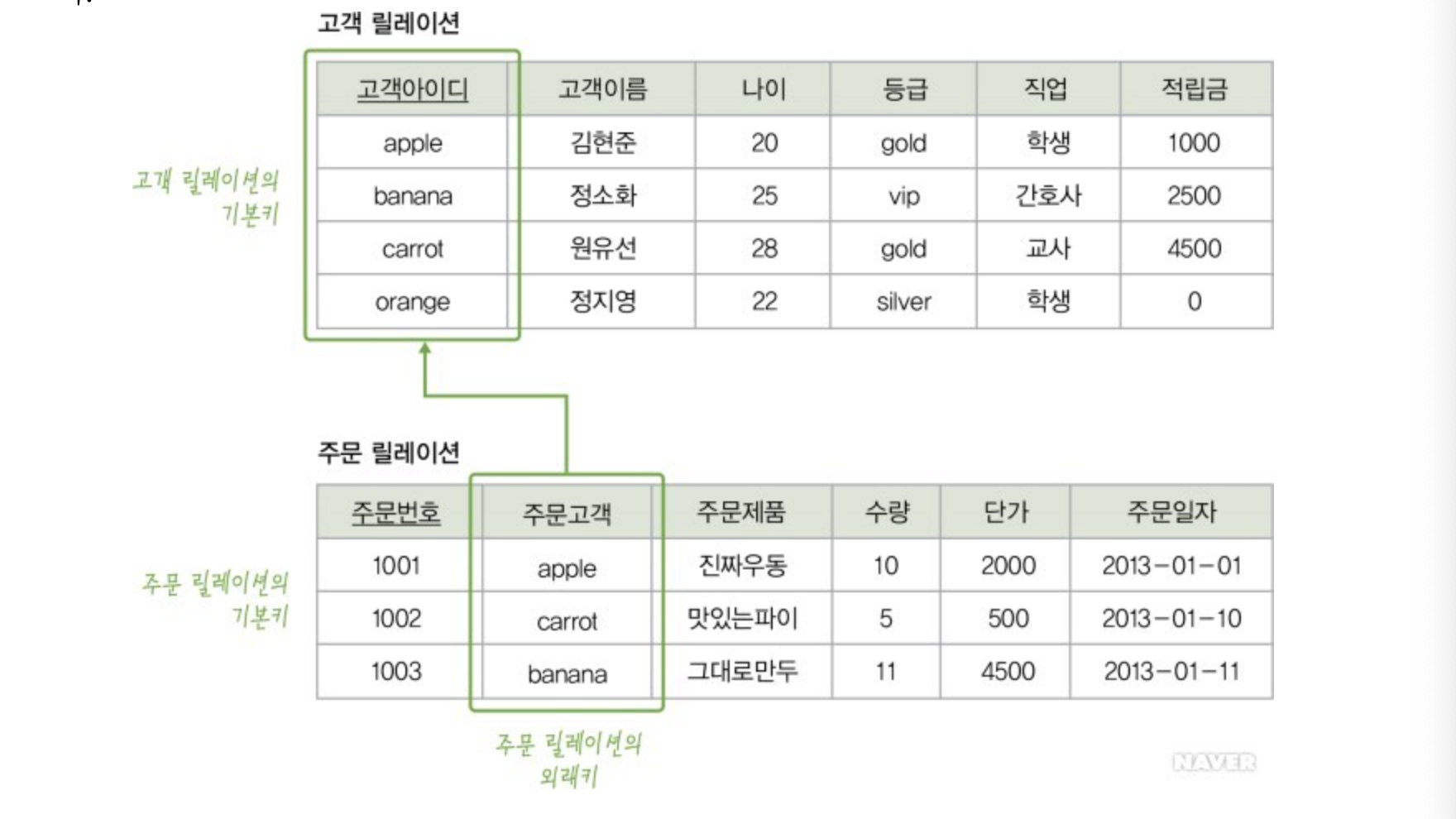
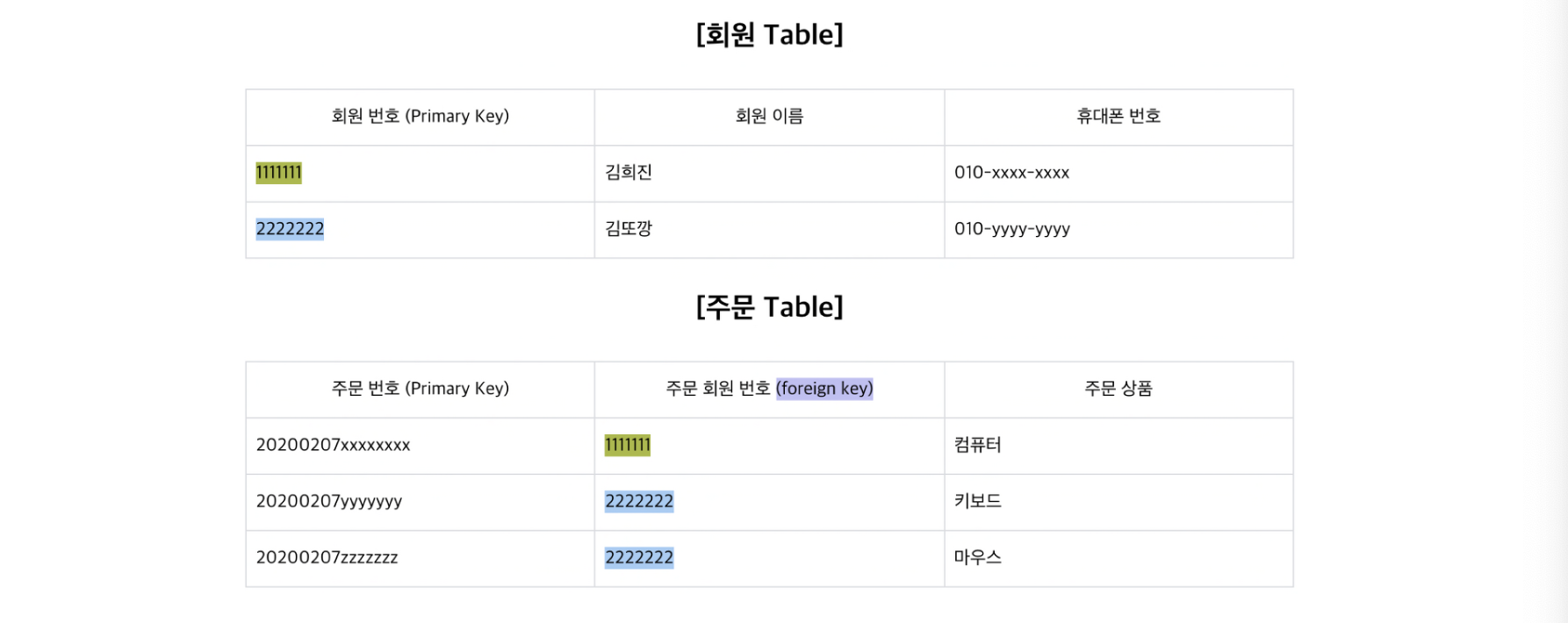
외래키(Foregin Key)
어떤 릴레이션간의 기본키를 참조하는 속성. 테이블들 간의 관계를 나타내기 위해서 사용된다.
다른 릴레이션의 기본 키를 그대로 참조하는 속성의 집합을 의미.
외래키가 되는 속성과 기본키가 되는 속성의 이름은 달라도 되지만, 외래키의 속성의 도메인과 참조되는 기본키 속성의 도메인은 반드시 같아야 한다. 도메인이 같아야 연관성 있는 투플을 찾기 위한 비교 연산이 가능하기 때문이다.
외래키가 없으면 2013년 1월1일에 제품을 주문한 고객의 이름을 검색할 수 없지만, 외래키가 있어서 이 날짜에 주문한 고객이 김현준임을 쉽게 알 수 있다.
외래키는 기본키를 참조하지만 기본키가 아니기 때문에 null값을 가질 수 있고, 서로다른 투플이 같은 값을 가질 수 있다.
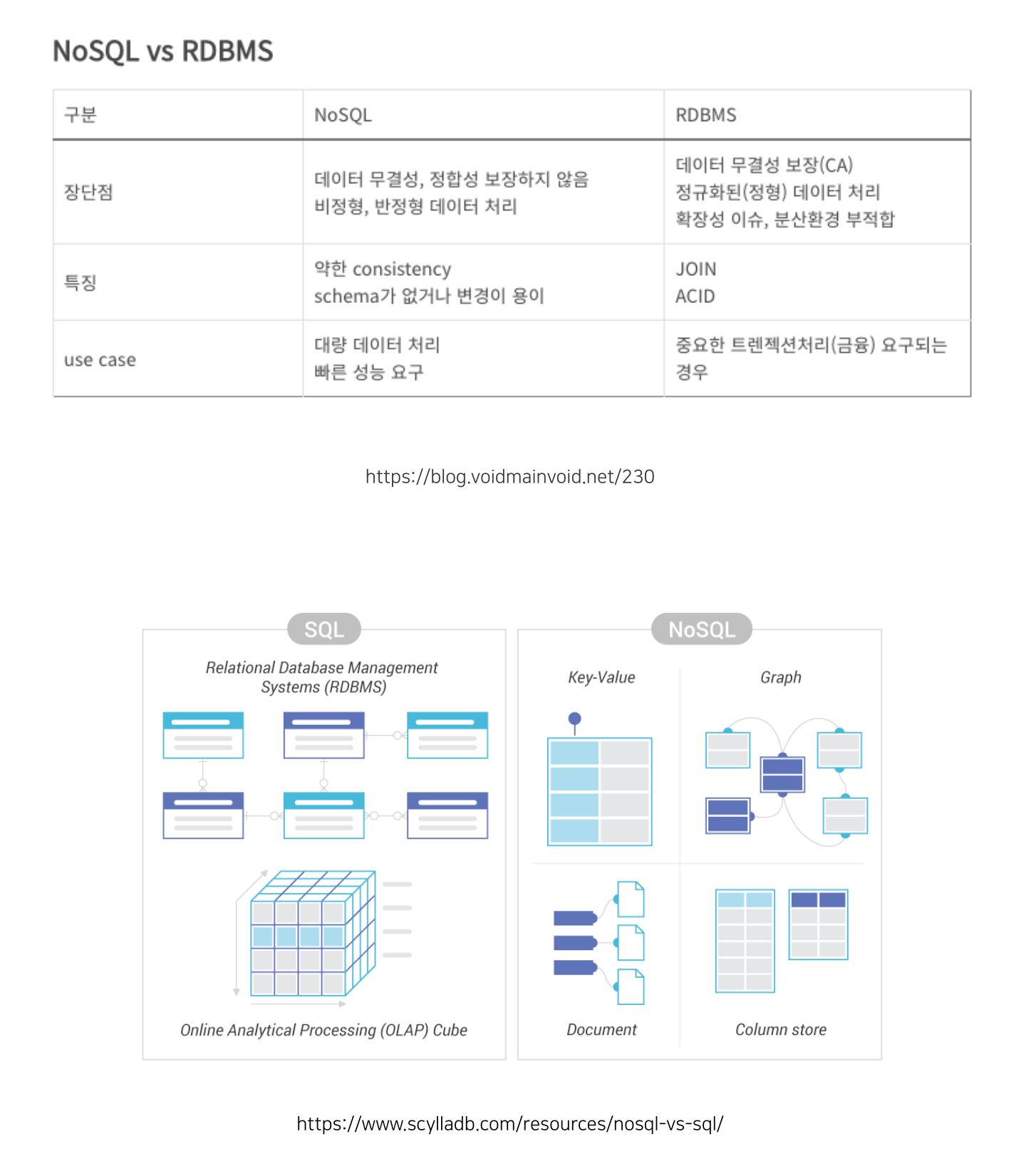
RDB vs NoSQL
RDB VS NoSQL에 대해서
- RDB(관계형 데이터베이스)를 RDBMS(데이터베이스를 관리)로 생성하고 수정하고 관리한다. SQL은 RDBMS를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어다
- NOSQL(비관계형 데이터 베이스)는 RDB 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장방식
DB의 종류
SQL
- MySQL,SQLite,postgreSQL
no-SQL(운영 DB모델기준 구분)
document: 정해진 모양 종류(정해진 컬럼없이) 저장가능 (mongo DB)
key-value: 쓰기, 읽기 겁나빠름 하지만 어떻게 꺼내야 할지 미리 저장하기전 생각하고 만들어야함. (DynamoDB)
column-oriented: 쓰기, 읽기 겁나빠름 하지만 어떻게 꺼내야 할지 미리 저장하기전 생각하고 만들어야함. (카산드라)
graphDB: column과 document가 필요없을때 사용→ 각 노드의 관계를 알아야할때 사용. (페이스북의 Tao)
NoSQL DB별 특성(아래보다 훨씬더많은 NoSQL 데이터 모델가진것있음)
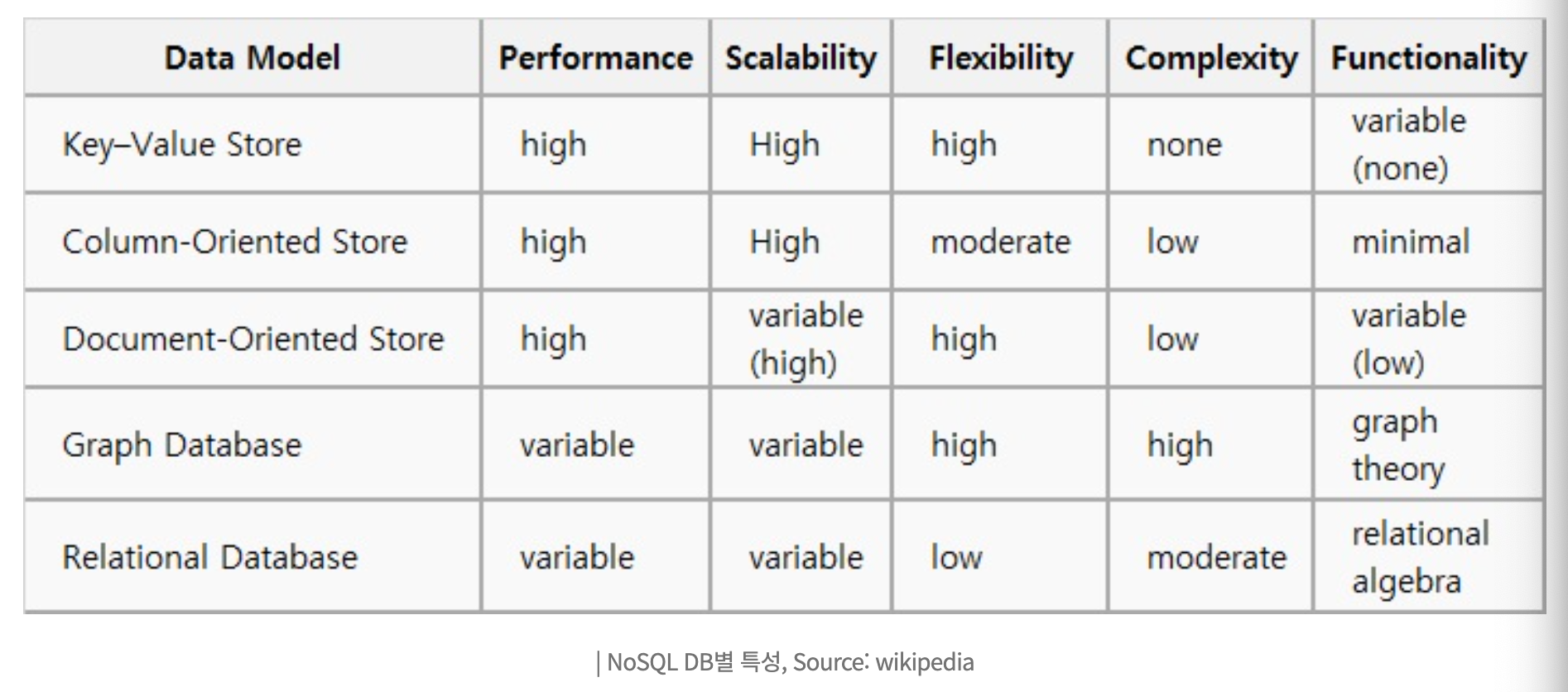
RDB의 특성
RDB
관계형 데이터 모델을 기초로 두고 모든 데이터를 2차원 테이블 형태로 표현하는 DB
스키마를 반드시 갖는다(테이블의 구조와 데이터 타입 사전정의됨)
- 데이터베이스를 구성하는 레코드의 크기, 키(key)의 정의, 레코드와 레코드의 관계, 검색 방법 등을 정의한 것을 말한다.
구성된 테이블이 다른 테이블들과 관계를 맺고 모여있는 집합체
이러한 관계를 나타내기 위해 외래 키(Foreign Key) 사용
이러한 테이블간의 관계에서 외래 키를 이용한 테이블 간 Join이 가능하다는것이 특징(테이블 결합기능)
RDBMS(Relational Database Management System)
- 사용자의 요구에 따라 정보를 생성해 관계형 데이터베이스를 생성하고 수정하고 관리할 수 있는 소프트웨어
- Mysql, Oracle Database, SQLite, PostgreSQL 등등
SQL
- 데이터베이스 관리 시스템(RDBMS) 의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어이며 관계형 데이터베이스 관리 시스템에서 자료의 검색과 관리,데이터베이스 스키마 생성과 수정, 데이터베이스 객체 접근 조정 관리를 위해 고안
트랜잭션과 ACID성질
- 트랜잭션이란 여러 개의 작업을 하나로 묶은 실행 유닛을 말한다
- 하나의 트랜잭션에 속해있는 여러 작업중 하나라도 실패하면 이 트랜잭션에 속한 모든 작업을 실패한것으로 판단(모든 작업이 성공해야 이 트랜잭션성공)
- 트랜잭션 결과는 성공 or 실패이다.(미완료된 작업없이 모든 작업성공해야함)
- 트랜잭션이랑 DB의 상태를 변환시키는 기능을 수행하기 위한 하나 이상의 쿼리를 모아 놓은 하나의 작업단위를 말한다.
- RDB트랜잭션은 ACID 라는 특성을 가진다
- ACID는 DB 내에서 일어나는 하나의 트랜잭션의 안전성을 보장하기 위해 필요한 성질이다.(주식거래, 금융업에서 중점사용 >> RDB사용하여 상호 작용하는 방식 정확하게 규정하여, 예외적인 상황 줄이고, DB의 무결성 보호
- Atomicity (원자성)
- Consistency (일관성)
- Isolation (격리성, 고립성)
- Durability (지속성)
원자성
- 원자성이란 시스템에서 한 트랜잭션의 연산들이 모두 성공하거나, 반대로 전부 실패되는 성질을 말한다.
- 원자성은 작업이 모두 반영되거나 모두 반영되지 않음으로서 결과를 예측할 수 있어야 한다.
- 작업A, 작업B 쿼리가 있을때 특정쿼리가 실패하면, 모든작업을 실패하게 만들어 기존 데이터를 보호한다(롤백시킨다)
일관성
- 일관성은 하나의 트랜잭션 이전과 이후, 데이터베이스의 상태는 이전과 같이 유효해야 한다.
- 다시 말해, 트랜잭션이 일어난 이후의 데이터베이스는 데이터베이스의 제약이나 규칙을 만족해야 한다는 뜻이다.
- 모든 고객은 반드시 이름을 가진다 제약있다면, 기존고객 이름 삭제 쿼리, 이름 없는 새로운 고객을추가하는 트랜잭션이있다면 일관성 위반
고립성,격리성
- 격리성은 모든 트랜잭션은 다른 트랜잭션으로부터 독립되어야 한다는 뜻이다.
- 실제로 동시에 여러 개의 트랜잭션들이 수행될 때, 각 트랜젝션은 고립(격리)되어 있어 연속으로 실행된 것과 동일한 결과를 나타낸다.
- 철저히 독립적이기에 다른 트랜젝션의 작업 내용알수없다.
지속성
- 지속성은 하나의 트랜잭션이 성공적으로 수행되었다면, 해당 트랜잭션에 대한 로그가 남아야하는 성질을 말한다.
- 만약 런타임 오류나 시스템 오류가 발생하더라도, 해당 기록은 영구적이어야 한다는 뜻이다.
- 예를 들어 은행에서 게좌이체를 성공적으로 실행한 뒤에, 해당 은행 데이터베이스에 오류가 발생해 종료되더라도 계좌이체 내역은 기록으로 남아야 한다.
- 마찬가지로 계좌이체를 로그로 기록하기 전에 시스템 오류 등에 의해 종료가 된다면, 해당 이체 내역은 실패로 돌아가고 각 계좌들은 계좌이체 이전 상태들로 돌아가게 된다.(롤백)
NoSQL의 특성
- SQL을 사용하지 않는 데이터베이스 관리 시스템(DBMS)을 지칭하는 단어
- RDB 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장
- 비관계형 DB+비구조적인 데이터저장을 위한 분산 저장 시스템
- join도 당연히 불가능
- 스키마
- NoSQL이 SQL과 반대되는 개념처럼 사용된다고 해서, NoSQL에 스키마가 반드시 없는 것은 아니다.
- 관계형 데이터베이스에서는 데이터를 입력할 때 스키마에 맞게 입력해야 하는 반면, NoSQL에서는 데이터를 읽어올 때 스키마에 따라 데이터를 읽어 온다.
- 읽어올 때에만 데이터 스키마가 사용된다고 하여, 데이터를 쓸 때 정해진 방식이 없다는 의미는 아니다. 데이터를 입력하는 방식에 따라, 데이터를 읽어올 때 영향을 미친다.
- 일관성을 희생해 가용성을 최대화하도록 설계되어있음.
- RDB는 일관성은 모든 읽기 작업이 DB에 기록된 가장 최근 데이터를 반환해야 한다는 생각
- noSQL은 최종 일관성을 목표로한다. 최종 일관성은 새로 작성된 데이터가 반드시 즉시 사용할 수있어야하는것은 아니지만, 결국 DB의 다른 노드에서 사용할 수 있게됨(보통 ms내)을 의미한다.
- 직접 프로그래밍을 하는 등의 No-SQL 인터페이스를 통한 데이터 액세스
- 대부분 여러 대의 데이터베이스 서버를 묶어서(클러스터링) 하나의 데이터베이스를 구성(스케일 아웃 용이)
- Data처리 완결성 미보장 (RDB는 Transaction ACID 지원)
- 데이터의 스키마와 속성들을 다양하게 수용 및 동적 정의 (Schema-less)
- 데이터베이스의 중단 없는 서비스와 자동 복구 기능지원
NoSQL과 RDBMS 특성차이
데이터 저장(Storage)
- NoSQL은 key-value, document, wide-column, graph 등의 방식으로 데이터 모델로 저장한다.
- 관계형 데이터베이스는 SQL을 이용해서 데이터를 테이블에 저장한다. 미리 작성된 스키마를 기반으로 정해진 형식에 맞게 데이터를 저장해야 한다.
스키마(Schema)
- SQL을 사용하려면, 고정된 형식의 스키마가 필요하다. 다시 말해, 처리하려는 데이터 속성별로 열(column)에 대한 정보를 미리 정해두어야 한다.
- RDB의 스키마는 나중에 변경할 수 있지만, 이 경우 데이터베이스 전체를 수정하거나 오프라인(down-time)으로 전환할 필요가 있다.
- NoSQL은 관계형 데이터베이스보다 동적으로 스키마의 형태를 관리할 수 있다.
- NoSQL은 행을 추가할 때 즉시 새로운 열을 추가할 수 있고, 개별 속성에 대해서 모든 열에 대한 데이터를 반드시 입력하지 않아도 된다.
쿼리(Querying)
- 쿼리는 데이터베이스에 대해서 정보를 요청하는 질의문이다.
- 관계형 데이터베이스는 테이블의 형식과 테이블간의 관계에 맞춰 데이터를 요청해야 한다. 그래서 정보를 요청할 때, SQL과 같이 구조화된 쿼리 언어를 사용한다.
- 비관계형 데이터베이스의 쿼리는 데이터 그룹 자체를 조회하는 것에 초점을 두고 있다. 그래서 구조화 되지 않은 쿼리 언어로도 데이터 요청이 가능하다. UnQL(UnStructured Query Language)
확장성(Scalability)
- 일반적으로 SQL 기반의 관계형 데이터베이스는 수직적으로 확장하다.
- 높은 메모리, CPU를 사용하는 확장이라고도 한다. 데이터베이스가 구축된 하드웨어의 성능을 많이 이용하기 때문에 비용이 많이 든다.
- 여러 서버에 걸쳐서 데이터베이스의 관계를 정의할 수 있지만, 매우 복잡하고 시간이 많이 소모된다.
- NoSQL로 구성된 데이터베이스는 수평적으로 확장한다.
- 보다 값싼 서버 증설, 또는 클라우드 서비스 이용하는 확장이라고도 한다.
- NoSQL 데이터베이스를 위한 서버를 추가적으로 구축하면, 많은 트래픽을 보다 편리하게 처리할 수 있다.
- 그리고 저렴한 범용 하드웨어나 클라우드 기반의 인스턴스에 NoSQL 데이터베이스를 호스팅할 수 있어서, 수직적 확장보다 상대적으로 비용이 저렴하다.
SQL 기반의 관계형 데이터베이스를 사용하는 케이스
1. 데이터베이스의 ACID 성질을 준수해야 하는 경우
2. 소프트웨어에 사용되는 데이터가 구조적이고 일관적인 경우
NoSQL 기반의 비관계형 데이터베이스를 사용하는 케이스
- 데이터의 구조가 거의 또는 전혀 없는 대용량의 데이터를 저장하는 경우
- 클라우드 컴퓨팅 및 저장공간을 최대한 활용하는 경우
- 빠르게 서비스를 구축하는 과정에서 데이터 구조를 자주 업데이트 하는 경우
다운타임(데이터베이스 서버를 오프라인으로 전환하여 데이터 처리 진행하는 작업시간) 없이 데이터 구조를 자주업데이트하는경우, 스키마를 매번 수정해야 하는 광계형 데이터베이스보다 NoSQL 기반의 비관계형 데이터베이스를 사용하는게 적합
Sqlite vs MySql vs progreSql
SQLite
- 낮은 메모리 환경에서도 이식성, 안정성, 강력한 성능으로 잘알려짐
- ACID준수함
- Serverless DB로 SQLite사용시, DB에 엑세스하는 모든 프로세스가 DB 디스크 파일을 직접 읽고 쓴다.
- 데이터 타입 Null, interger, real, txt, blob
장점
- 매우 가볍다. SQLite 작동 위해 시스템에 설치해야 하는 외부 종속성없다
- Zero-configuration로 서버 프로세스가 필요없으므로 시작, 재시작, 구성 파일 없음
- 이식성 높음: SQLite는 단일 파일에 전체 데이터가 저장된다. 어디에나 위치가능
단점
- 동시성 제한 → 동시에 여러 프로세스가 SQLite DB에 엑세스 쿼리가능하지만 주어직시간에 하나의 프로세스만이 DB변경가능
- 사용자 관리 부재 → 파일엑세스만 되면 모두 사용가능
- 보안 취약 → 버그로부터 불안전
사용하면 좋은 경우
- 임베디드 애플리케이션 → 이식성높고, 향후 확장 필요없음
- 테스트 환경 → 인메모리 모드 지원, 다른 DB는 대부분 애플리케이션에서 추가 서버 프로세스를 사용하는 DBMS로 테스트는 과하다.
사용하면 안되는경우
- 많은 데이터 작업이 요구되는 경우
- 높은 볼륨 쓰기가 요구되는 경우 → SQLite는 지정된 시간에 하나의 쓰기 작업만 수행할수있으므로 처리량 크게 제한됨. 많은 쓰기 작업 및 동시에 여러 작업은 부적합
- 네트워크 액세스 필요한 경우 → 서버없으므로 직접적인 네트워크 액세스 제공X
MySql
- MySQL의 데이터 타입 3가지 → numeric 타입, date&time 타입, string 타입
- 최근 버전은 ACID준수
장점
- 보안 수준 높은 DB(사용자 관리 지원)(암호 보안 수준 설정)(루트 사용자 암호 정의)
- 속도 빠름
- 복제기능 지원(안정성, 가용성, 내결함성을 향상하기 위해 두개 이상의 호스트에서 정보를 공유하는 방식인 여러 유형의 복제 기능지원)(비동기 방식)
단점
- 제한 기능 존재(Full Join절에 대한 지원X)
- 라이선스 및 독점 기능제약
- 느린 개발
사용하면 좋은 경우
- 분산 작업 필요한경우 → 복제 기능 지원은 분산 DB설정 가능→수평적 확장 용이
- 웹 사이트 웹 애플리케이션 적합 → 쉽고, 확장성 좋음
사용하면 안되는경우
- SQL 준수가 필요한 경우 → MySql은 전체 표준 SQL을 구현하지않음
- 동시성과 대용량 데이터 볼륨이 요구되는 경우→ MySQL은 동시에 읽기와 쓰기 작업이 일어나는 경우 안됨→ PostgreSQL같은 다른 RDBMS가 적합
PostgreSql
- 확장성이 뛰어나고, 표준을 준수한다. (RDB+ 객체 DB와 연관된 기능포함)(테이블 상속 및 함수 오버로딩 가능)
- 동시성 → ACID준수하는 MVCC(Multiversion Concurrency Control) 덕분에 읽기에 대한 잠금없이 달성가능하다.
- 데이터 타입은 숫자, 문자열, 날짜와 시간 타입 3가지 +도형, 네트워크 주소, 비트 문자열, 텍스트 검색, JSON 항목 다양한 데이터 타입 지원
MVCC란?
동시 접근을 허용하는 DB에서 동시성을 제어하기 위해 상요하는 방법
데이터에 접근하는 사용자는 접근 시점에서 DB의 Snapshot을 읽는다. 이 snapshot 데이터에 대한 변경이 완료될 때(트랜잭션이 commit될때)까지 변경사항은 다른 데이터 베이스 사용자가 볼수없다. 이제 사용자가 데이터를 업데이트하면 이전 데이터를 덮어 씌우는게 아니라 새운 버전의 데이터(version혹은 UNDO영역)를 생성한다. 이전 버전 데이터와 비교해서 변경된 내용을 기론한다. 해서 하나의 데이터에 대해 여러 버전의 데이터가 존재하게 되고, 사용자는 마지막 버전의 데이터를 읽게된다 → Lock방식보다빠름, 사용하지않는 데이터가 쌓이므로 정리하는 시스템 필요, 데이터버전충돌시 애플리케이션 영역에서 문제 해결해야함
장점
- 표준 SQL 준수한다(SQList, MySQL보다 나음)
- 오픈소스 DB
- 확장성 뛰어남
단점
- 메모리 성능이 떨어진다.(모든 새로운 클라이언트 연결에 대해 PostgreSQL은 새로운 프로세스를 포크(fork)합니다. 각각의 새로운 프로세스에는 약 10MB의 메모리가 할당되므로 많은 연결이 있는 경우 메모리가 빠르게 증가합니다.)→ 간단한 작업의 경우 성능 떨어짐(???)
- 인기도 낮음
사용하면 좋은 경우
- 데이터 무결성이 중요한 경우 → ACID를 완벽히 준수하고 데이터 일관성이 유지되도록 MVCC를 구현하였다.
- 다른 도구들과 통합되어야 하는 경우 적합 → 다양한 프로그래밍 언어와 플랫폼호환됨
- 복잡한 작업 연산을 수행하는 경우 적합하다.→ 여러 CPU를 활용할수있는 쿼리 계획지원→ 동시 사용자에 지원, 트랜잭션 처리 적합
사용하면 안되는경우
- 속도에 민감한 경우 → 속도를 희생하여 확장성과 호환성을 염두하고 설계되었다. 빠른 읽기X
- 간단한 설정이 필요한 경우 → 광범위한 기능과 표준 SQL에 대한 준수로 설정에 많은 작업 필요
- 간단한 복제 작업을 원하는 경우 → 강력한 복제 기능은 지원하지만, 일부 구성(primary-primary)만 가능, 복제의 경우 MySQL이 용이
No-SQL 데이터 모델별 차이
Key-Value DB
- 연관 배열(Associative Array)(Dictionary or Hash table)을 관리하고 저장함으로 동작함
- 연관 배열에 키가 고유 식별자 역할을 하며, 키와 값이 한쌍으로 이 쌍들의 모음으로 DB구성됨. 값은 정수, 문자열, JSON구조 모두 지원
- 구조나 관계없이 데이터를 단일 컬렉션으로 저장하며, 서버 연결후 키를 정의, 값을 제공할수도있다.
- Key-Value DB는 내부에 보관된 모든 데이터를 불투명한 Blob처리한다.
- 구조를 어떻게 이해하는지는 애플리케이션에 달려있다
장점
- 성능 뛰어나고 효율적이며 확장 가능하다.
- 일반적으로 캐싱, 메시지 대기열(Queuing), 세션 관리) 에 용이
대표적인 DB
- Redis: 데이터베이스, 캐시, 메시지 브로커로 사용되는 인메모리 저장소. 문자열, 비트맵, 스트림, 공간 인덱스까지 다양한 데이터 구조를 지원합니다.
- Memcached: 메모리에 데이터와 개체를 캐싱하여 데이터 기반의 웹사이트와 애플리케이션의 속도를 높이는데 자주 사용되는 범용 메모리 개체 캐싱 시스템.
- Riak: 고급 로컬 및 다중 클러스터 복제 기능이 있는 분산 Key-Value 데이터 베이스.
Local Cache vs Global Cache
데이터의 일관성이 깨져도 비즈니스에 영향을 주지 않는가? 에대해서 생각해보고 고르자
Local Cache는 각 서버의 메모리에 캐시 저장소를 두어 서버가 여러대일경우 일관성을 해칠수있다. 하지만 오버헤드가없고, 빠르다
Global Cache는 외부에 캐시 서버를 둠으로써 서버가 여러대여도 동일한 캐시 저장소에 접근하기 떄문에 , 데이터 일관성을 보장할수있다. 하지만 네트워크 I/O비용이 발생한다.
Columnar DB
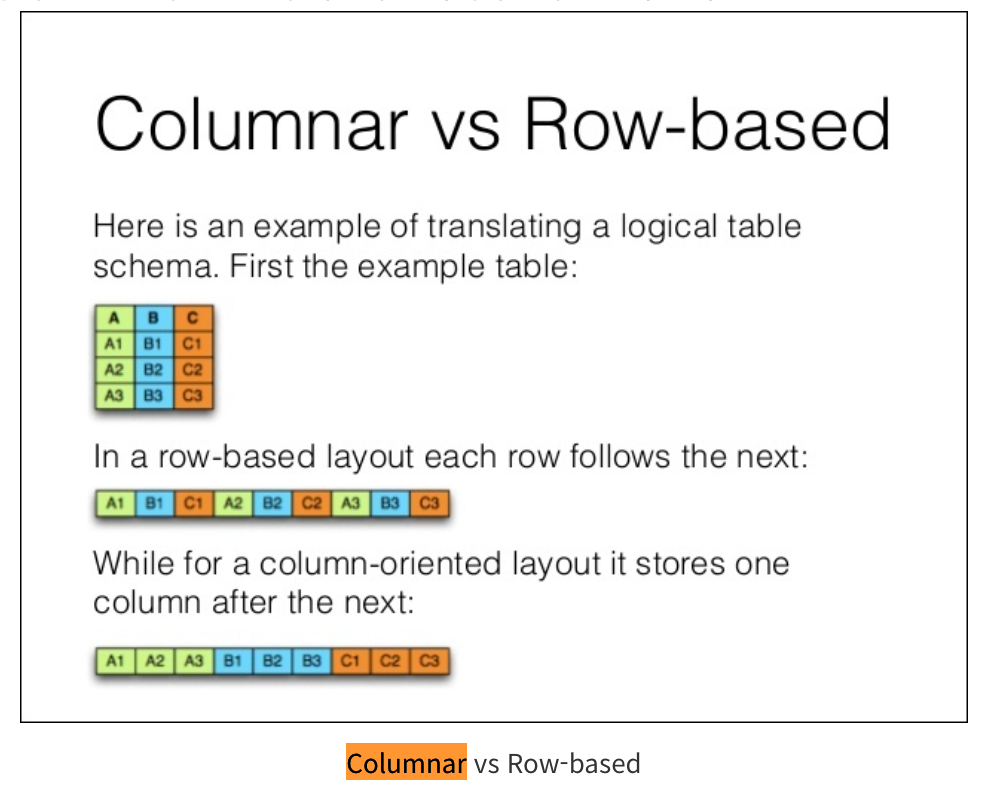
- 열(Column)에 데이터를 저장하는 DB 시스템(RDB와의 차이는 열을 테이블로 그룹화하는 대신 각각의 열은 시스템 저장소의 별도의 파일 또는 영역에 저장한다)
장점
- 필요한 열만 읽을수있다(쿼리가 모든 행을 읽고 메모리에 저장된후 불필요한 데이터를 삭제할필요없다)
- 각 열의 데이터는 동일한 유형이므로 저장 및 읽기 최적화 전략사용가능
단점
- 각 열을 개별적으로 작성해야 하고 압축된 상태로 유지되기 때문에 성능이 좋지않다.
- 특히 개별 레코드 읽기는 비용많이든다
대표적인 DB
- Apache Cassandra: 확장성, 가용성, 성능을 극대화하도록 설계된 열 기반 저장소입니다.
- Apache HBase: 대용량 데이터에 대해 구조화된 스토리지를 지원하고 Hadoop과 함께 동작하도록 설계된 분산 데이터베이스입니다.
- ClickHouse: 분석 데이터 및 SQL 쿼리의 실시간 생성을 지원하는 내결함성(Fault tolerant) DBMS입니다.
Document
- 문서 기반(Document-oriented) DB는 데이터를 문서 형태로 저장하는 No-SQL이다
- 문서 저장소는 Key-Value저장소의 한 유형이므로 각 문서는 고유한 Key가있으며, 문서 자체가 Value 역할을 한다
- 문서 기반 DB는 각 문서에 일정 수준의 구조를 제공하는 메타 데이터 포함되어 검색할수있는 API 또는 쿼리 언어 제공 및 문서 내에 다른 문서 중첩가능
- 반면, Key-Value DB는 데이터가 불투명하게 처리되므로 그 안에 보관된 데이터를 신경쓰지않는다(무슨 데이터인지도모름)(오직 애플리케이션이관리)
- 주어진 객체의 모든 데이터를 단일 문서에 저장가능하다.
- RDB같은 경우는 주어진 객체의 데이터가 여러 테이블이나 다른 DB에 분산될수있는 관계존재가능
- Key값은 Document가 될수있다(Embedded Document)
- Key에 대한 값은 배열이 될수있으며, 배열의 값으로 Document를 포함할수있다.
- 마치 관계형 DB에서의 여러개 테이블 데이터를 하나의 Document로 모을수있다.
장점
- 확장성이 높다 → 유연한 스키마(애초에 스키마없음)
- 구조가 다르고 복잡한 정보 보관 탁월
대표적인 DB
- MongoDB: 이 글이 쓰였을 땐 이 범용 분산 문서 기반 데이터 베이스인 MongoDB가 세계에서 가장 널리 사용되던 문서 기반 데이터베이스였습니다.
- Couchbase: 원래 Merbase로 알려졌으며 JSON 기반의 Memcached와 호환되는 문서 기반 데이터베이스로 알려졌습니다. 다중 모델 데이터베이스인 Couchbase는 Key-Value 데이터베이스로도 동작할 수 있습니다.
- Apache CouchDB: Apache SW Foundation의 프로젝트인 CouchDB는 데이터를 JSON문서로 저장하고 JS를 쿼리 언어로 사용하는 문서 기반 데이터베이스입니다.
그래프(???)
- 문서에 데이터를 저장하고 데이터가 미리 정의된 스키마를 따르지 않는다는 점에서 문서 기반 데이터 모델의 하위 범주 + 개별 문서 간의 관계를 강조해 문서 모델에 별도의 레이어가 추가된다!!(다른점)
- 추가 개념
- Node: 노드. 노드는 그래프 데이터베이스에서 추적하는 개별 엔티티의 표현입니다. 관계형 데이터베이스의 레코드, 행(row) 문서 기반 데이터베이스의 문서 개념과 거의 같습니다. 예를 들어 음악을 녹음하는 아티스트의 그래프 데이터베이스에서 노드는 연주자나 밴드가 될 수 있습니다.
- Property: 속성. 속성은 개별 노드와 관련된 정보입니다. 위의 예를 다시 사용하면 보컬리스트, 재즈, 플래티넘 인증 음악가 등이 될 수 있습니다.
- Edge: 그래프 또는 관계(Relationship)로 알려진 에지는 두 노드가 어떻게 관련되어 있는지를 나타내며 RDBMS와 문서 기반 데이터베이스와 구별되는 그래프 데이터베이스의 핵심 개념입니다. 에지는 방향이 지정되거나 지정되지 않을 수도 있습니다.
- Undirected: 무방향성. 방향성이 없는 그래프에서 에지는 노드 간의 연결을 표시하기 위해 존재합니다. 이 경우 에지는 양방향의 관계로 생각할 수 있습니다. 한 노드가 다른 노드와 어떻게 관련이 있는지에는 암시적인 차이점이 없습니다.
- Directed: 방향성. 방향성 그래프에서 에지는 관계가 시작된 방향에 따라 다른 의미를 가질 수 있습니다. 이 경우 에지는 단방향의 관계로 생각할 수 있습니다. 예를 들어 방향성 그래프에서 Sammy가 그룹을 위해 앨범을 제작한 경우 Sammy와 Seaweeds의 관계를 방향성을 통해 지정할 수 있지만 Seaweeds에서 Sammy로의 방향성의 의미는 앞의 경우와 동등하지 않습니다.
- 특정 작업은 관련 정보를 연결하고 그룹화하는 방식 때문에 그래프 데이터베이스를 사용하는 것이 훨씬 간단합니다. 이러한 데이터베이스는 일반적으로 데이터 포인트 간의 관계에서 무언가를 얻어야 하거나 엔드 유저가 사용할 수 있는 정보가 소셜 네트워크처럼 다른 사람과 연결에 의해 정해지는 경우에 사용됩니다. 주로 사기 감지, 추천 엔진, ID 및 액세스 관리 애플리케이션에서 사용됩니다.
대표적인 DB
- Neo4j: 네이티브 그래프 저장 및 처리 기능을 갖춘 ACID 호환 DBMS입니다. 이 글이 작성될 때 Neo4j는 세계에서 가장 인기 있는 그래프 데이터베이스였습니다.
- ArangoDB: ArangoDB는 그래프, 문서 기반, Key-Value 데이터 모델을 하나의 DBMS로 통합하는 다중 모델 데이터 베이스이며 배타적인 그래프 데이터베이스가 아닙니다. SQL과 유사한 쿼리 언어인 AQL, 전체 텍스트 검색, 랭킹 엔진이 특징입니다.
- OrientDB: OrientDB는 그래프, 문서 기반, Key-Value, 객체 모델을 지원하며 또 다른 다중 모델 데이터베이스입니다. SQL 쿼리, ACID 트랜잭션을 지원합니다.