
왜?
- 클린 아키텍처는 무엇인지?
- DDD에 대한 추가적인 학습.
용어정리
- 계층형 아키텍처: 웹 -> 도메인 -> 영속성 등 각 계층을 책임에 따라 분리후 역할 기능만 수행한다.
- 클린 아키텍처: 의존성 방향이 내부방향(도메인)로만 이뤄져있는 구조. 외부 애플리케이션이나 기술 등에 의존되지 않으며, 비즈니스 규칙 생성 및 테스트하기 좋은 구조
1. 계층형 아키텍처의 문제는 무엇일까?
- 전통적인 계층 구조는 웹 → 도메인 → 영속성
- 웹: 요청을 받아 도메인 혹은 비즈니스 계층에 있는 서비스로 요청 역할
- 도메인: 필요한 비즈니스 로직을 수행하고, 도메인 엔티티의 현재 상태를 조회하거나 변경하기 위해 영속성 계층의 컴포넌트 호출
- 영속성: DB와의 통신으로 조회 및 커밋
- 계층형 아키텍처는 데이터베이스 주도 설계를 유도한다.
- 도메인 모델 추출후, 행동 중심으로 모델링한다. → 하지만, ORM를 보통 사용하므로 결국 DB 테이블과의 밀접한 관계를 맺기때문에, 데이터베이스의 구조를 먼저 생각후, 도메인 로직을 구현한다.
- 지름길을 택하기 쉬워진다.
- 추가적인 기능 구현이 필요할 때 영속성 계층에 추가하는 것이 가장 쉬운길이기 때문에 비대해질 가능성이 크다. → 어느계정에도 속하지 않는 것처럼 보이는 헬퍼, 유틸리티도 영속성계층이 될확률이 높다
- 테스트하기 어려워진다.
- 웹계층 → 영속성 계층으로 바로 참조하여 개발한 경우에도, 도메인 계층을 거치지 않기때문에, 결국엔 도메인 로직드링 웹계층으로 분산된다.
- 이제 웹 계층 테스트시, 도메인+영속성 계층도 모킹해야한다.
- 유스케이스를 숨긴다.
- 계층형 아키텍처는 도메인 로직이 여러 계층에 걸쳐있을수있어서, 유스케이스에 대응하는 로직이 정확한 위치를 찾는것이 어렵다. → 따라서 서비스가 비대해지기도한다.
- 동시 작업이 어려워진다
- 결국 영속성 계층이 만들어져야지만 → 서비스 → 웹계층을 개발할수있기때문에, 같은 서비스를 분산해서 개발할수없다.
2. 의존성 역전하기
프로세스 진행방향(화살표)를 반대로 바꾸는 방법
단일 책임 원칙
- 하나의 컴포넌트는 하나의 일만수행
의존성 역전 원칙
- 계층형 아키텍처는 계층 간 의존성은 항상 다음 계층인 아래 방향을 가르킨다.
- 이를 인터페이스 + 주입을 이용하여 방향 변경이 가능하다
- [서비스 → 리포지토리 구현체] ⇒ [서비스 → 리포지토리 인터페이스 <- 리포지토리 구현체]
클린 아키텍처란?
종속성 규칙(Dependency Rule)을 지키는 것.
각 코드의 종속성은 외부에서 내부로 안쪽으로만 가리킬 수 있고, 고수준 정책(High level policy)이 저수준 정책(Low level policy)의 변경에 영향을 받지 않도록 하는 것입니다.여기서 의미하는 수준(Level)은 입/출력과의 거리를 의미하는 것으로,
고수준 정책은 보통 UI 또는 인터페이스와 거리가 먼 비즈니스 영역 Business Rules, Entities 등을 의미하며,
저수준 정책은 위와 반대로 거리가 가까운 인프라 영역이나 UI 영역 Presentation, Controllers 등을 의미한다.아아키텍처에서는 설계가 비즈니스 규칙의 테스트를 용이하게 하고, 비즈니스 규칙은 프레임워크, 데이터베이스, 기술, 그밖의 외부 애플리케이션이나 인터페이스로부터 독립적일수있다.
즉, 도메인 코드가 바깥으로 향하는 어떤 의존성도 없어야한다.
의존성 역전 원칙의 도움으로 모든 의존성이 도메인 코드를 향해야한다.
헥사고날 아키텍처는 클린 아키텍처에 속한다.
- 코어(도메인계층+유스케이스[=서비스])으로 포트-어텝터 패턴 사용
3. 코드 구성하기
- 계층으로 구성하기
- web, domain, persistence로 계층(패키지)인 폴더 트리
- 기능(유저, 계좌 등등) 별로 서비스가 섞이기 쉬운 구조
- 기능으로 구성하기
- account 패키지 안에 Controller, Repository, RepositoryImpl, Service 등 존재
- 계층보다 아키텍처의 가시성을 떨어트린다.
- 표현력있는 패키지 구조
- account라는 폴더 상위 폴더(기능별 폴더)
- adapter(어뎁터)(코어X)
- in
- out
- domain(도메인)(코어O)
- application(애플리케이션, 서비스, 유스케이스)(코어O)
- Service
- port
- in
- out
- adapter(어뎁터)(코어X)
- account라는 폴더 상위 폴더(기능별 폴더)
4. 유스케이스 구현
- 유스케이스는 비즈니스 로직
- 단계
- 입력을 받는다
- 비즈니스 규칙을 검증한다(단순한 입력 유효성검증 X)
- 모델 상태를 조작한다
- 출력을 반환한다.
- 입력 유효성 검증
- 입력 유효성과 비즈니스 규칙 검증의 차이는 실제 모델에서 조회해서 검증해야하는지 여부의 차이다.
- 입력 모델(INPUT)은 코어계층에 속하며, 생성자에서 검증을 추천한다.(SelfValidating)
- 유스케이스마다 다른 입력 모델 추천
- 비즈니스 규칙 검증하기
- 유스케이스에서의 유효성 검증: “출금 계좌는 초과 인출되어서는 안된다” 처럼 모델에 접근한 후에 가능한 검증
- 입력 모델에서의 입력 유효성 검증: 모델 접근 필요없는 경우
- 풍부한 도메인 모델 vs 빈약한 도메인 모델
- 유스케이스마다 다른 출력 모델
- 출력 모델 또한 코어계층에 속한다.
- 읽기 전용 유스케이스는 어떨까?
- 개인적으로 쿼리 서비스 같은경우는 UseCase → Query로 하여, 간단하게 쿼리하여 출력
5. 웹 어댑터 구현하기
의존성 역전
- [컨트롤러 → 서비스] 외부요청에서 애플리케이션으로 요청이 흐른다.(의존성 방향 = 진행방향)
- 의존성 역전을 통해 [컨트롤러(어뎁터) → 포트 ← 유스케이스(서비스)]로 위치시키면 코어를 지킬 수
있다.
웹 어댑터의 책임
- HTTP 요청의 자바 객체로 매핑
- 권한 검사
- 입력 유효성 검증
- 입력을 유스케이스의 입력 모델로 매핑
- 유스케이스 호출
- 유스케이스의 출력을 HTTP로 매핑
- HTTP 응답을 반환
웹 어뎁터의 입력 모델과 유스케이스의 입력모델 차이
- 유스케이스의 입력 모델로 변환할 수있다는 것을 고려(검증필요)
컨트롤러 나누기(테스트등의 용이성, SRP)
6. 영속성 어댑터 구현하기
의존성 역전
- [서비스 → 영속성계층] ⇒ [서비스 → 포트 ← 영속성 어댑터(아웃고잉 어뎁터)]
영속성 어댑터의 책임
- 입력을 받는다
- 입력을 데이터베이스 포맷으로 매핑한다
- 입력을 데이터베이스로 보낸다
- 데이터베이스 출력을 애플리케이션 포맷으로 매핑한다
- 출력을 반환한다.
영속성 어댑터의 입력 모델은 반드시 애플리케이션 코어에 있어야한다. → 영속성 어댑터 내부변경이 코어에 영향이없다.
포트 인터페이스 나누기
- ISP 원칙에 따라 UseCase별로 인터페이스 분리해서 아웃 고잉포트를 적용해야한다
- AccountRepository 에 Register, Update 등에 필요한 모든 메서드가 포함된경우, 각 UseCase에서는 AccountRepository하나에만 의존하게됨 → 지양
- Repository하나로 넓은 곳에서 사용하는것은 코드에 불필요한 의존성이 생기는 방향
- ISP 원칙에 따라 UseCase별로 인터페이스 분리해서 아웃 고잉포트를 적용해야한다
영속성 어댑터 나누기
DDD영속성 연산에 필요한 도메인 클래스(애그리거트) 하나당 하나의 영속성 어댑터를 구현하는 방식을 선택할 수있다.
- AccountPersistenceAdapter, UserPersistenceAdapter
도메인 코드는 영속성 포트에 의해 정의된 명세를 어떤 클래스가 충족시키는지는 관심이없다.
애그리거트당 하나의 영속성 어댑터 접근 방식은 나중에 여러 개의 바운디드 컨텍트(bounded context)의 영속성 요구사항 분리하기 위한 좋은 토대다.
각 바운디드 컨텍스트는 영속성 어댑터를 하나씩 가지고있다. 경계 기준이된다.
account, billing 맥락의 영속성 어댑터에 서로 접근하지않는다.
어떤 맥락이 다른 맥락의 무엇인가를 필요로 한다면 전용 인커밍 포트를 통해 접근해야한다
데이터베이스 트랜잭션은 어떻게 해야할까?
- 애플리케이션 계층(Service, UseCase)에서 에너테이션을 적용하는것이 바람직하다.
7. 아키텍처 요소 테스트하기
- 테스트 피라미드(given, when, then)
- 단위 테스트: 단 하나의 클래스가 제대로 동작 테스트(단 하나의 클래스와 의존성은 mock처리)
- 도메인 엔티티
- 유스케이스
- 통합 테스트: 두 계층 간의 경계를 걸친 테스트
- 컨트롤러
- @WebMvcTest
- 영속성 어댑터
- @Import
- @DataJpaTest
- DB를 모킹하지않고, 실제로 DB접근까지 확인 한다.
- 컨트롤러
- 시스템 테스트: 애플리케이션을 구성하는 모든 객체 네트워크 가동시켜, 특정 유스케이스가 전 계층이 동작하는 테스트
- 통합 유스케이스별 테스트(요청부터 json응답까지)
- @SpringBootTest
- 통합 유스케이스별 테스트(요청부터 json응답까지)
- 단위 테스트: 단 하나의 클래스가 제대로 동작 테스트(단 하나의 클래스와 의존성은 mock처리)
- 통합테스트로 웹 어댑터 테스트하기
- 얼마만큼의 테스트가 충분할까?
- 도메인 엔티티를 구현할 때는 단위 테스트를 커버하자
- 유스케이스를 구현할 때는 단위 테스트를 커버하자
- 어댑터를 구현할 때는 통합 테스트를 커버하자
- 사용자가 취할 수 있는 중요 애플리케이션 경로는 시스템 테스트로 커버하자
- 개발 중에 테스트를 짜야(TDD) 개발 도구로 느껴질것이다.
- 최대한 작은 범위 테스트는 60%, 큰 범위 테스트는 핵심만 지향하자
8. 경계 간 매핑하기
“매핑하지 않기” 전략
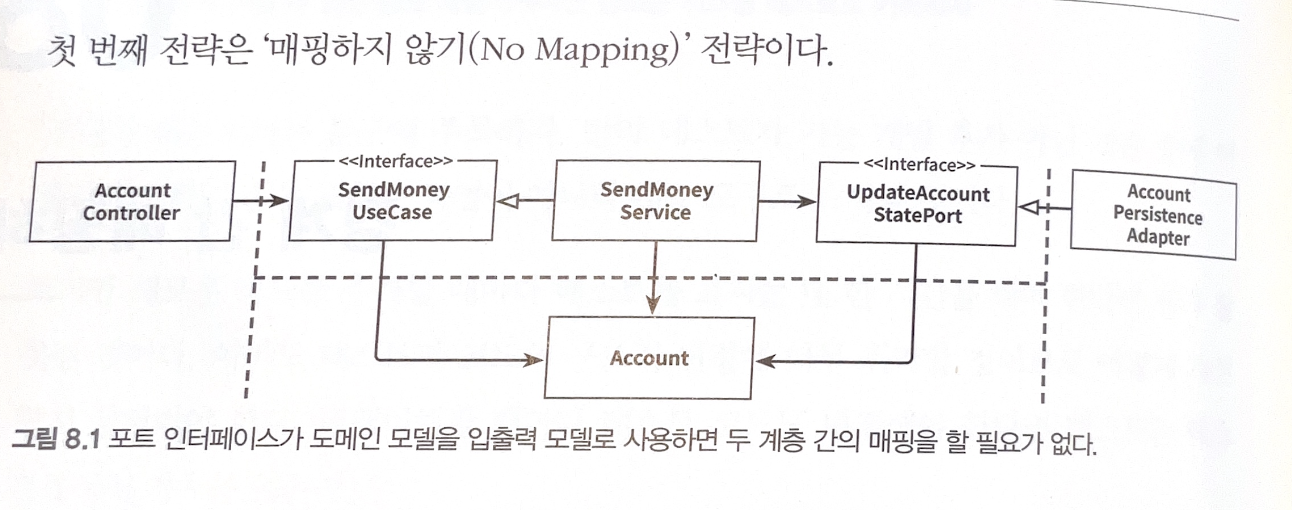
- 모든 계층 입출력 모델을 도메인 모델 사용
- (단점)웹 계층과 영속성 계층에서 요구하는 변경점이 생길경우, 도메인 모델 변경되어야함
- 빠른 개발 후 넘어가는 부분적으로 양방향 전략으로 넘어가는 과정 필요
“양방향” 매핑 전략
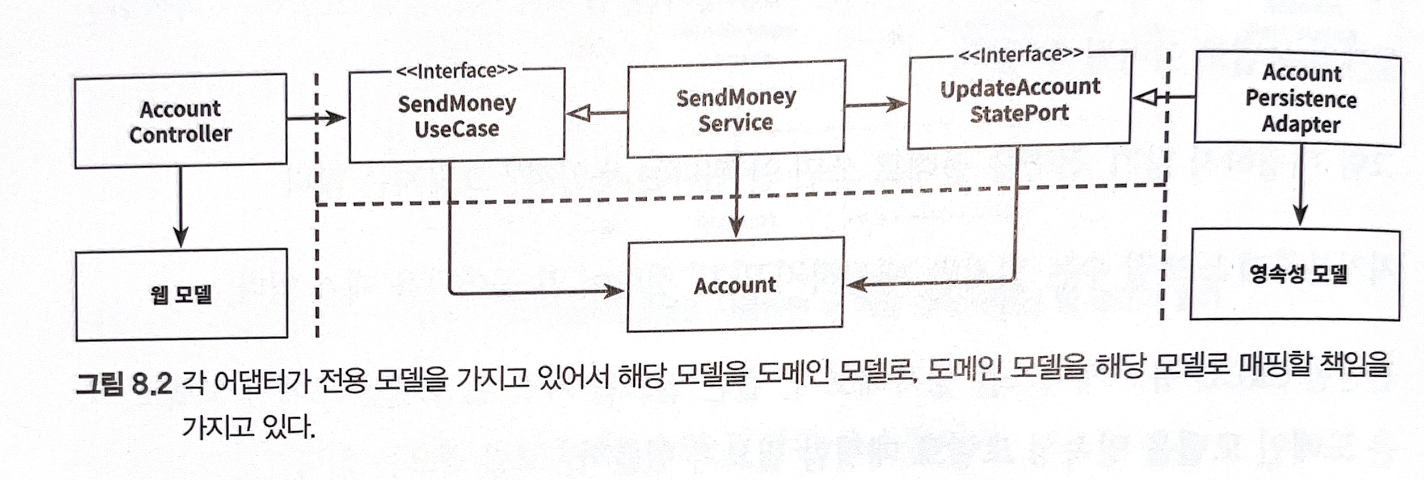
- 도메인 모델 ↔ 각 계층 모델간의 매핑 필수
- 장점
- 각 계층의 변경사항이 있어도, 도메인 모델에 변경을 유발하지않는다.
- 단점
- 각 모델별 매핑 필요 → 보일러플레이트 코드가 다수 발생
- 도메인 모델 계층이 인커밍 포트에서는 파라미터로, 아웃고잉 모델에서는 반환값으로 사용된다. 즉, 바깥쪽 계층의 요구에 따른 변경에 취약함
“완전” 매핑 전략
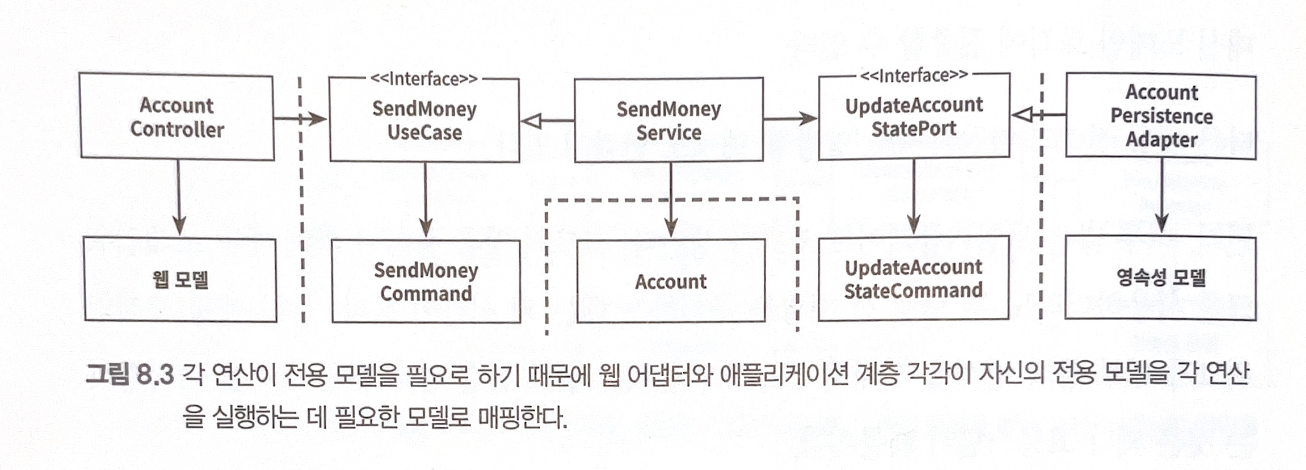
- 각 계층별 전용 모델 존재 및 계층 통과 시 필요한 모델(커맨드 혹은 리퀘스트라고 불림)을 정의하여 매핑
- SendMoneyUseCase 포트의 입력 모델로 특화된 SendMoneyCommand
- 이러한 전용 모델들은 각자의 전용필드 및 유효성 검증이 가능하다.
- 보통 코어 ↔ 영속성 계층 사이에서는 매핑 오버헤드 때문에 사용하지않는다.
- 입력adapter ↔ core계층 사이에서는 더 명확한 검증 책임 등을 구별할수있기 때문에 사용을 고려하자
- 각 계층별 전용 모델 존재 및 계층 통과 시 필요한 모델(커맨드 혹은 리퀘스트라고 불림)을 정의하여 매핑
“단방향” 매핑 전략
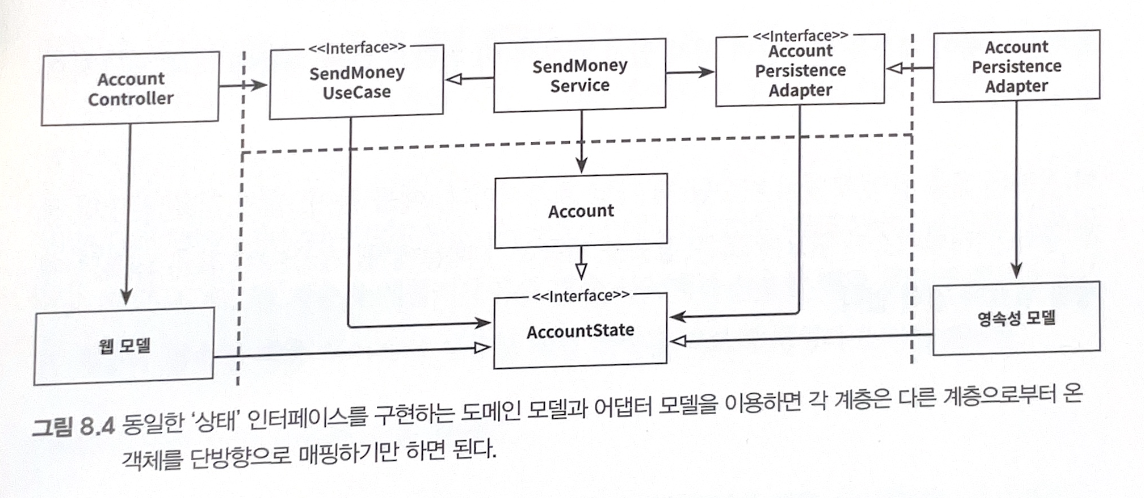
- 모든 계층의 모델을 단일 인터페이스로 정의
언제 어떤 매핑 전략을 사용할 것인가?
- 그때그때 다르다.
9. 애플리케이션 조립하기
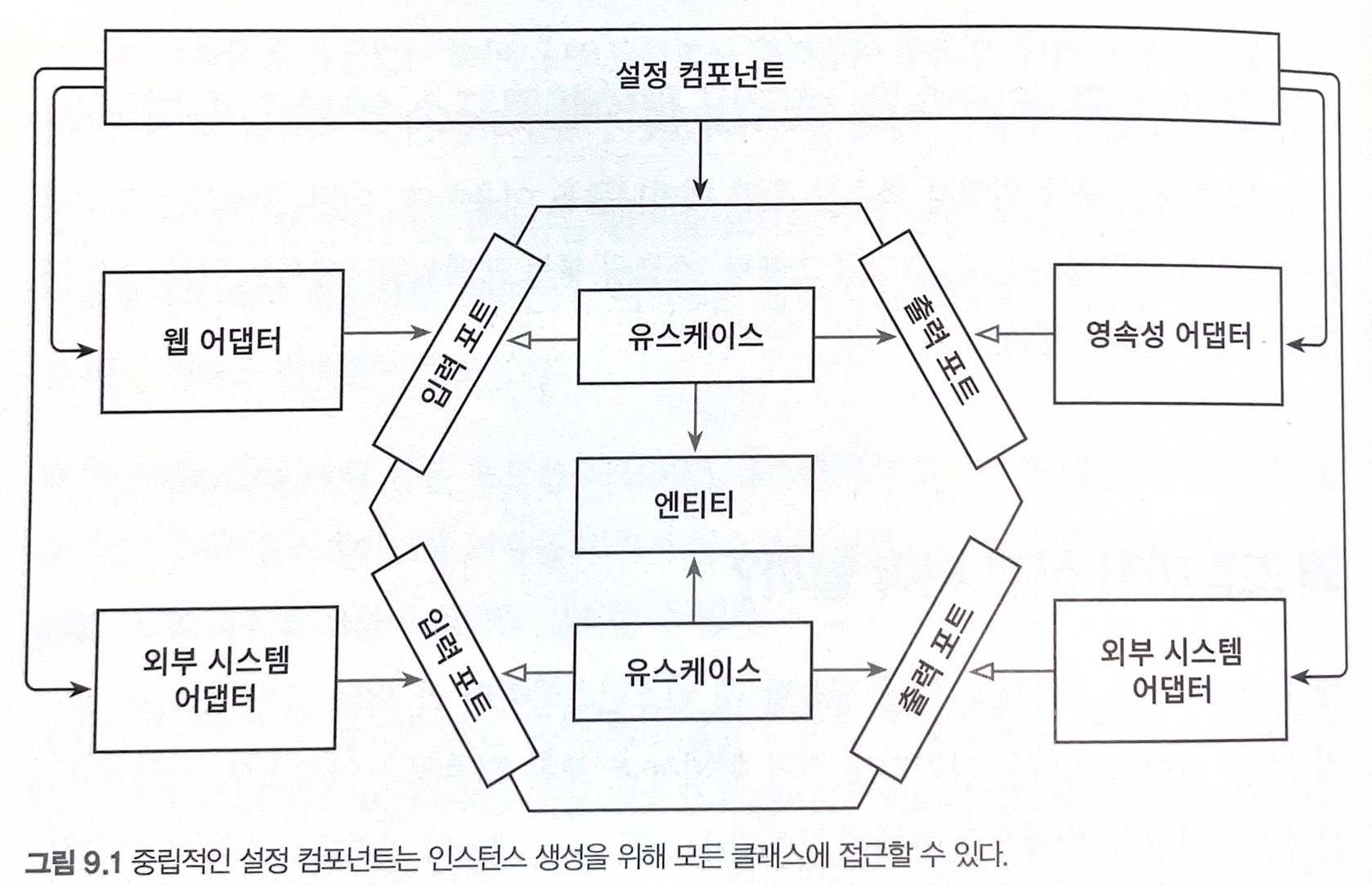
- 평범한 코드로 조립하기
- 스프링의 클래스패스 스캐닝으로 조립하기
- @Component
- 단점
- 어떤 것들이 Bean으로 생성되었는지 관리 못할가능성있음
- 스프링의 자바 컨피그로 조립하기
- @Configuration
- 장점
- 내가 의도한 객체를 Bean으로 등록해줌
10. 아키텍처 경계 강제하기
경계와 의존성
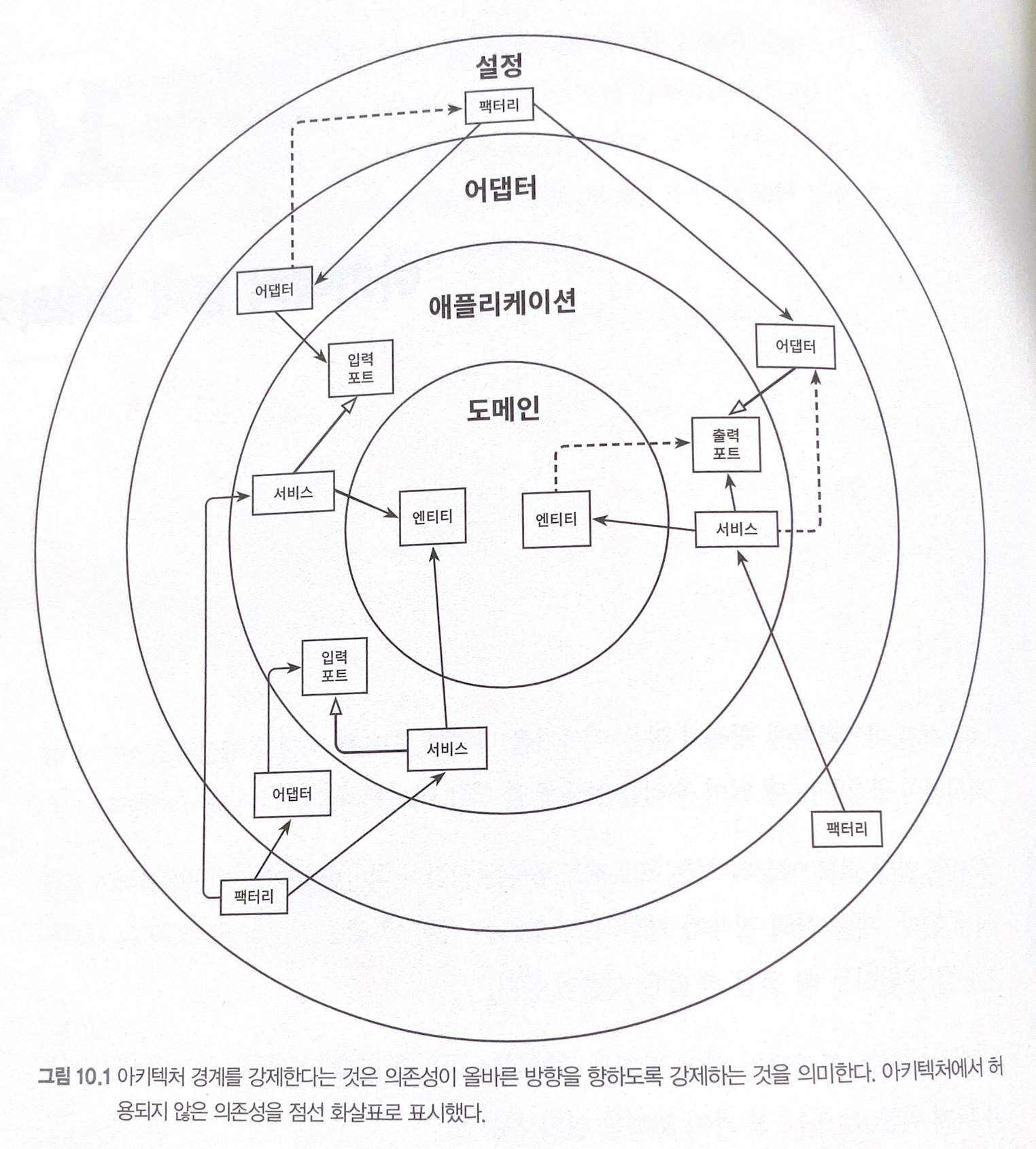
접근 제한자
- package-private 접근 제어자+ 스프링을 사용하여, 계층의 강제성을 부여가능하다.

컴파일 후 체크(나중에 학습하기)
- ArchUnit
빌드 아티팩트
- 여러 개의 분리된 빌드 아티팩트를 통해서, 의존성을 분리하여 각 계층의 영향도 낮춤
11. 의식적으로 지름길 사용하기
- 왜 지름길은 깨진 창문 같을까?
- 깨끗한 상태로 시작할 책임
- 유스케이스 간 모델 공유하기
- 유스케이스마다 다른 입출력 모델을 가져야 매우 독립적이다.
- 하지만 변경할 이유가 동일하다면, 실제로 두 유스케이스에 모두 영향을 주고싶은게 의도되었다면 상관없다.
- 도메인 엔티티를 입출력 모델로 사용하기
- 간단한 개발시에는 요청사항이 엔티티 변경사항과 일치하여 입력모델 또한 도메인 엔티티를 사용하는것 간단하지만, 시간이 지날수록 영향도가 생긴다면, 전용 모델로 교체해야한다.
- 인커밍 포트 건너뛰기
- 인커밍 어뎁터에서 포트없이 코어(서비스)에 붙는경우, 추상화 계층이 없으므로, 전용 모델을 쓰지도 못하고 구분점도 모호해진다. → 아키텍처 또한 무너지므로 지양
- 애플리케이션 서비스 건너뛰기
- 유스케이스에서 코어(서비스) 제외하고 영속성 어뎁터로 처리하는경우, 유스케이스를 판단하기어렵고, 아키텍처 또한 무너지기때문에 지양
12. 아키텍처 스타일 결정하기
- 도메인이 왕이다
- 도메인에 따라 다양한 도메인 로직 작성가능
- 입력, 출력과 상관없이 비즈니스 로직에만 집중가능한 구조
- 경험이 여왕이다.
- 헥사고날 경험해봐라. 소규모라도 도입
- 그때그때 다르다
- 어떨때는 계층형, 어떨때는 헥사고날 선택하자.
추가 참조사항
- 엔티티
- 개별성이 있는 엔티티이며, 속성들이 모두 각자 변화가능하다
- 값 객체
- 개별성이 없는 객체이며, 속성들이 한꺼번에 추가, 삭제된다.
- 구매에서 구매자, 구매자의 멤버쉽 등급, 구매품(상품, 가격), 수취자(이름, 주소)
- 값 객체의 특징
- 도메인 내의 어떤 대상을 측정, 수량, 설명한다
- 관련 특징을 모은 필수 단위로 개념적 전체를 모델링
- 측정이나 설명이 변경될 때는 완벽히 대체 가능하다
- 다른 값과 등가성을 사용해 비교
- 값 객체는 생성되면 변경될수없다.
- 개별성이 없는 객체이며, 속성들이 한꺼번에 추가, 삭제된다.
- 표준 타입
- 대상의 타입을 나타내는 서술적 객체다. 멤버쉽 등급 enum으로 하는것처럼 표준을 정의하는것
- 애그리거트
- 엔티티와 값 객체를 모델링하게 되면, 객체 간의 계층구조가 만들어지고, 연관된 엔티티와 값 객체들의 묶음이 애그리거트다
- 1~2개의 엔티티, 값 객체, 표준 타입등으로 구성된다. 비즈니스 정합성을 맞출 필요가있다.
- 따라서 애그리거트 단위가 트랜잭션의 기본 단위다.
- 애그리거트 내에서 가장 상위의 엔티티를 애그리거트 루트라고 정의한다.
- 루트를 통해서만 애그리거트 내의 엔티티나 값 객체를 변경가능하다
- 하나의 컨텍스트에 하나이상의 애그리거트가 존재가능하다. 하나의 애그리거트에서 다른 애그리거트를 참조해야한다면, 직접참조(클래스의 정의)가 아닌 간접참조(ID로 참조)하는것을 지향하자.
- 만약에 다른 애그리거트 사이에 일관성이 필요하다면 어떻게할까?
- A 애그리거트 -> 이벤트 발생 -> B 애그리거트 로 설계하면 애그리거트는 단일 트랜잭션 단위니까 결과적 일관성으로 애그리거트가 갱신된다.
- 도메인 서비스
- 비즈니스 로직 처리가 특정 엔티티나 값 객체에 속하지 않을떄, 단독 객체를 만들어서 처리하게 되는데, 이를 도메인 서비스라고한다. 도메인 서비스에서는 상태를 관리하지 않고, 행위만 존재한다.
- 도메인 로직을 처리할 때 엔티티나 값 객체와 함께 특정 작업을 처리하고 상태를 본인이 가지고 있지 않고 엔티티나 값 객체에 전달한다.
- 도메인 이벤트
- 도메인 이벤트는 DDD 및 이벤트 스토밍에서 말하는 도메인 이벤트의 구현 객체다. 서비스 간의 정합성을 일치시키기 위해 단위 애그리거트의 주요 상태 값을 담아 전달되도록 모델링 된다.
- 주문서비스에서 주문 트랜잭션 처리를 통해 주문 엔티티와 주문아이템 엔티티가 생성되어 저장됨과 동시에 -> [구매완료됨] 이벤트를 발생한다.
- 구매완료됨은 주요 주문 정보를 포함하고있다.
- 이벤트 발행은 주문 처리를 수행하는 트랜잭션과 묶어서 실행되어야한다.
- 이벤트는 메시지 메커니즘을 통해 다른 서비스에 전달되며 이를 통해 배송 서비스는 배송 처리를 수행할수있다.
- 도메인 이벤트는 DDD 및 이벤트 스토밍에서 말하는 도메인 이벤트의 구현 객체다. 서비스 간의 정합성을 일치시키기 위해 단위 애그리거트의 주요 상태 값을 담아 전달되도록 모델링 된다.