참조
배달의민족 라빈의 스프링 배치
왜?
사이드 프로젝트에서 spring-batch가 필요했다.
대법원 사이트에 들어가서 크롤링할 것들이 많았고, 이를 사프-DB에 저장해야하기 때문이다.
batch 특성상 대용량 데이터 처리에 적합하기 때문에 적합하다고 판단하였다.
배치 구성 및 요약
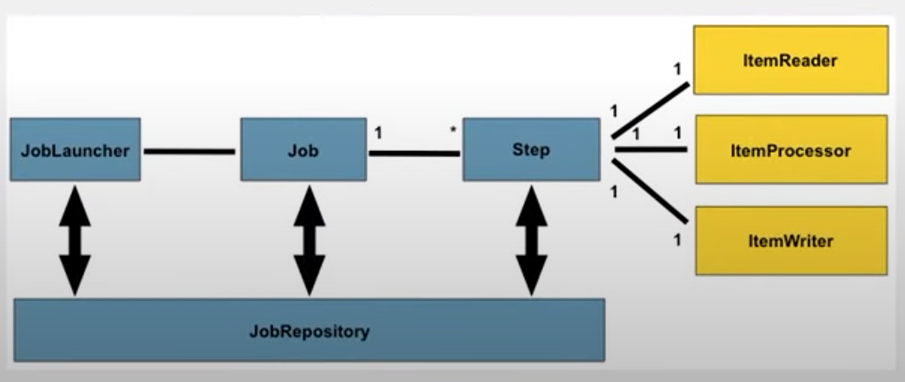
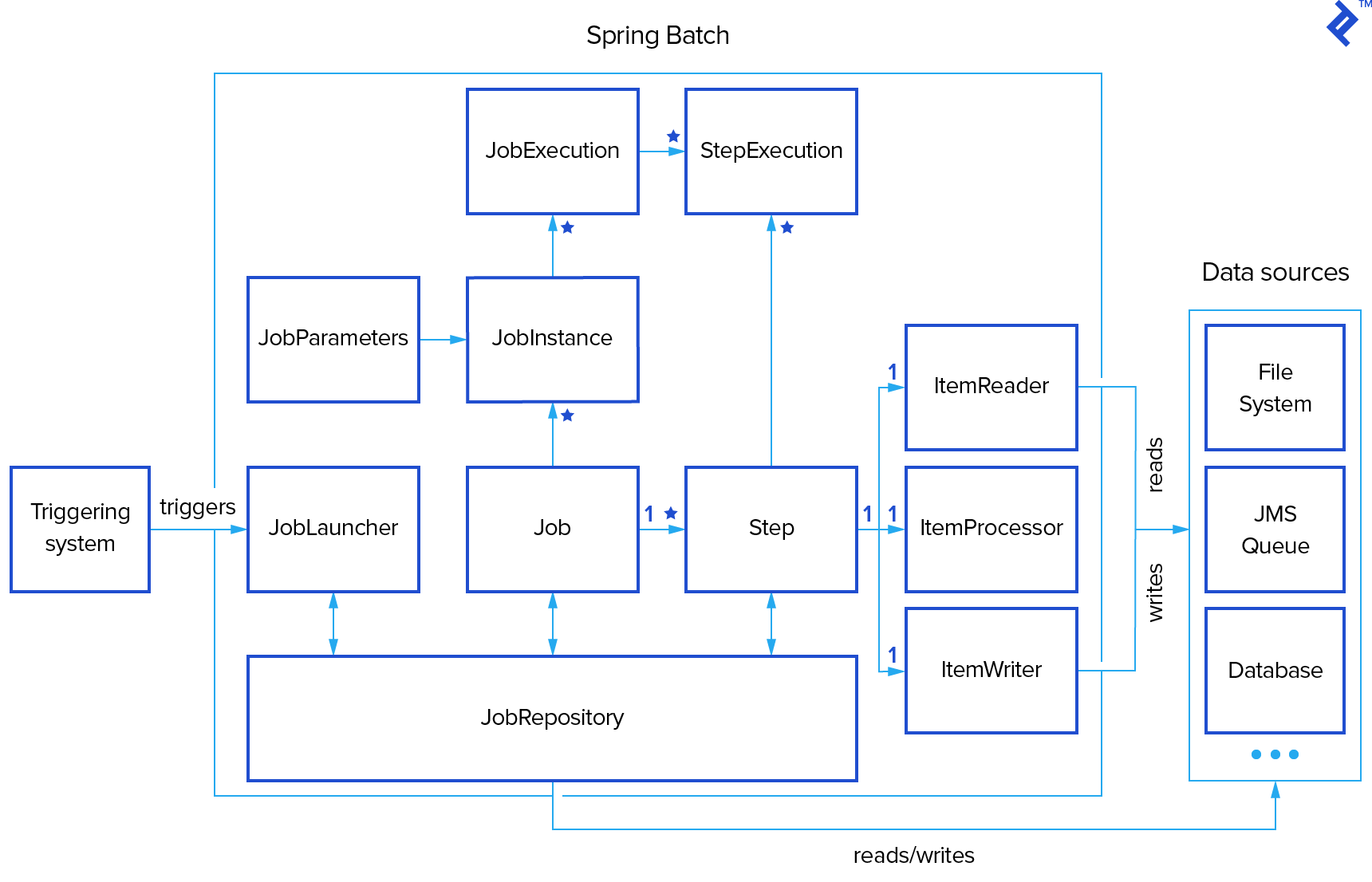
LobLauncher
JobRepository
- job, step excution 기록 역할
- job, step에 대한 성공, 실패, readcount, write count 등의 값을 DB에 기록해주고 있으며, 개발자가 비즈니스 로직에 집중할수있게 도와줌
Job
- Job
- JobInstance
- job+ identity값을 parameter로 유일한 특징이 있음.
- 예를 들면 2025년 1월 26일 00:00:00과 2025년 1월 27일 00:00:00는 다른 jobInstance
- JobExecution
- JobInstance 를 실행시켜주는 역할, 상태값을 가짐.
- DB에 상태값 기록됨
Step
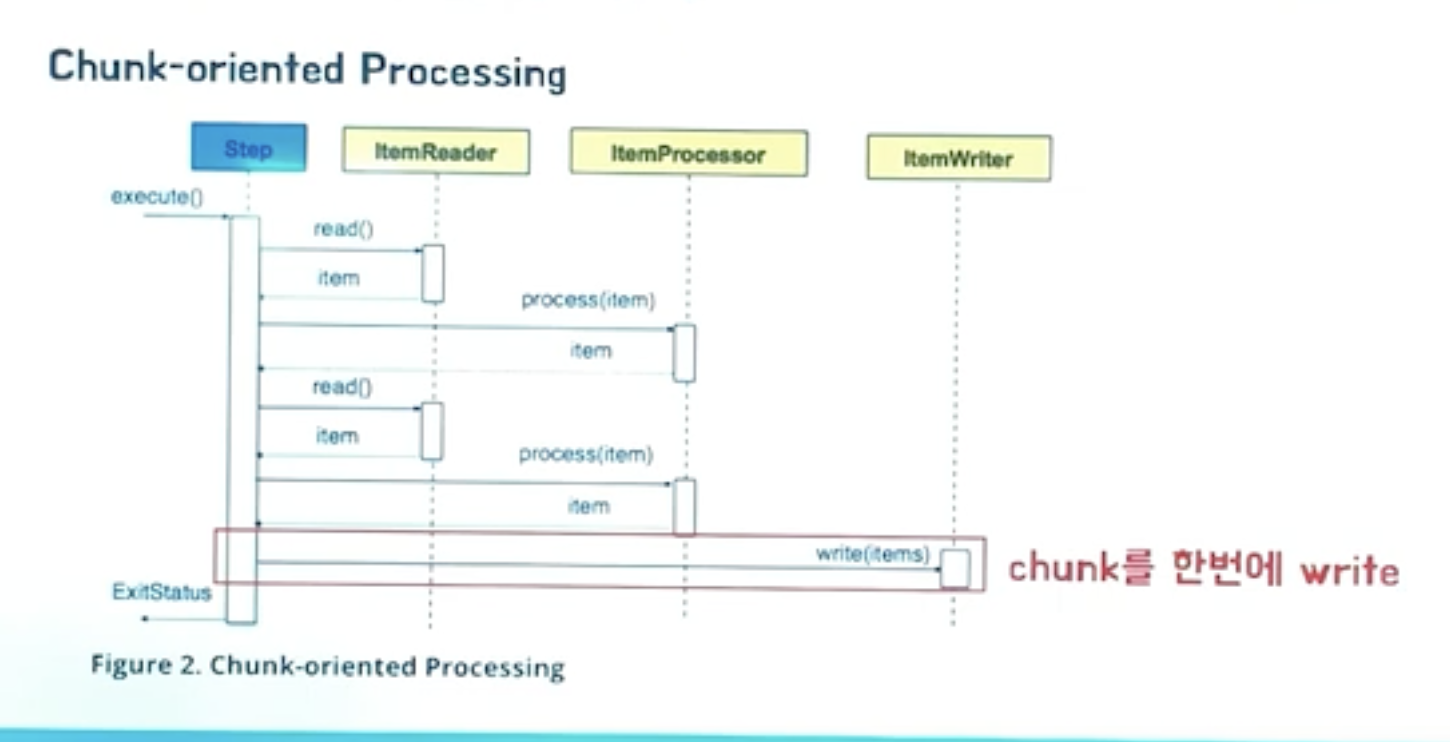
- Step
- StepExecution
- Step를 실행시켜주는 역할, 상태값을 가짐.
- DB에 상태값 기록됨
- ItemReader
- Step 부분 중 Item(대상 row 지칭)을 read하는 역할
- ItemProcessor
- Step 부분 중 read된 Item을 비즈니스 로직을 처리하는 역할
- Optional
- ItemWriter
- Step 부분 중 상태변화 완료된 Item(대상 row 지칭)을 기록하는 역할
예시
- “1~100 item 처리완료” 메시지 10개씩 10번 출력되는 배치잡이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
@SpringBootApplication
class SherbetBatchTestApplication
fun main(args: Array<String>) {
runApplication<SherbetBatchTestApplication>(*args)
}
@Configuration
@EnableBatchProcessing
class BatchConfig(
private val jobBuilderFactory: JobBuilderFactory,
private val stepBuilderFactory: StepBuilderFactory
) {
private val log = LoggerFactory.getLogger(BatchConfig::class.java)
private val jobName = "testTaskChunkJob"
@Bean
fun testTaskChunkJob(): Job {
return jobBuilderFactory.get(jobName)
.incrementer(RunIdIncrementer())
.start(chunkStep1())
.build()
}
@Bean
fun chunkStep1(): Step {
return stepBuilderFactory.get("chunkStep1")
.chunk<String, String>(10)
.reader(itemReader())
.processor(itemProcessor())
.writer(itemWriter())
.build()
}
private fun itemReader(): ItemReader<String> {
return ListItemReader(getItems())
}
private fun itemProcessor(): ItemProcessor<String, String> {
return ItemProcessor { item -> "$item 처리완료" }
}
private fun itemWriter(): ItemWriter<String> {
return ItemWriter { items -> log.info("### writer : ${items.toString()}") }
}
private fun getItems(): List<String> {
val items = mutableListOf<String>()
for (i in 1..100) {
items.add("item$i")
}
return items
}
}
|
추가적인 용어정리 및 팁
용어정리
- 청크(chunk): 각 커밋 사이에 처리될 row(item)의 수
- 성공시 chunk만큼 커밋, 실패시 chunk 만큼 롤백
- 페이징(paging): itemReader에서 제공하는 기능. read하는 item들의 갯수
팁
- 청크와 페이징 수는 반드시 동일해야한다.
- 성능이슈(JPA기준으로 청크 > 페이징일 경우 step이 끝나고 commit 일어나지않고, 다음 작업을 위해 reading하면 메모리에 2배의양이..로드됨)
